Building on from previous research and approaches to using machine learning for pentesting scenarios, this week our research team moves onto the architecture and design of the Project Ava ‘system’.
Read on to find out about the architectures tested and the team’s conclusions.
Overview
Unsurprisingly, machine learning requires data – lots of data, and that data must also be:
- Relevant – it must be current to the problem domain in which we’re operating.
- Representative – it must offer the same features of the types of data within the problem domain in which we’re operating.
- Realistic – it should comprise data that is real, taken from real-world applications.
In this post, we document the architecture and design of the Project Ava ‘system’ – the system being the technical manifestation of a capability allowing us to collect, consume and process web application data to generate machine-learned models that check for vulnerability in that data.
Data engineering – the many challenges…
Project Ava’s aim was to compliment manual web application security testing, fundamentally from a black box testing approach which involves us not having access to any application source code. The only data that we can therefore obtain from black box web application testing is that of the dynamic application itself, which is essentially served-up responses to HTTP requests in the guise of HTML and associated web content (JavaScript, CSS etc.).
Either this web content is manifested within a web browser for inspection and interaction, or more commonly from our security testing perspective, seen as web request/response pairs through use of a local intercepting proxy.
Burp Suite
NCC Group’s web application security testing tool of choice is Burp Suite [1]; a local intercepting prox. This tool provides us with full control over web requests and responses, is bundled with a number of useful functions, and importantly for us, allows for bespoke extensions to be programmed using an API into the data passing through the proxy. This means that we can have full control over web request/response pairs and their constituent parameters and values.
To satisfy the need for lots of data that is relevant, representative and realistic; we architected the following high-level design:
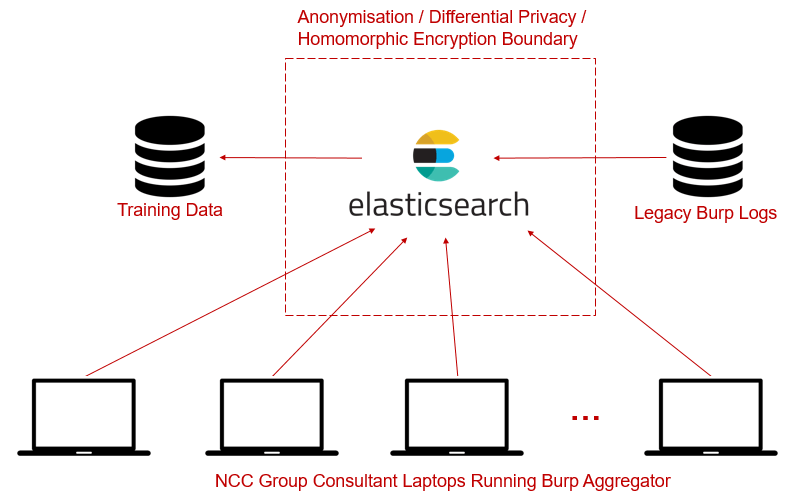
By virtue of NCC Group having one of, if not the largest application security testing teams in the world, our aim was to develop a method of crowd-sourcing web application data (Burp logs) from our large pool of specialists who routinely perform web application security tests against real-world systems across most sectors and technologies.
In addition, where client consent has been given over the years, we have access to some legacy burp logs from historical web application security assessments. A combination of crowd-sourced and legacy data would give us a corpus of data to be used to create training data.
We elected to use an on-premises elasticsearch [2] instance as the main consumer of all data sources, which would allow us to easily mine and extract the required features from web request/response pairs to be used as part of our training data.
Supervised Learning
While capturing large volumes of web requests/response pairs is easy, our main aim was to specifically capture examples of ‘known vulnerable’ web request/response pairs – i.e. when a consultant has confirmed that a particular vulnerability exists affecting a specific parameter (SQLi for example). We wanted a way to ‘tag’ the relevant request/response with the associated class of vulnerability, in a manner that was supervised. Our hypothesis was that with enough tagged data from different web applications, we would have good basis for training various models on what ‘vulnerable’ looks like. This would mean that we may be able to apply those models to auto-detect likely vulnerability in future web application security tests.
To support the architecture described above and to facilitate the ‘tagging’ of vulnerable request/response pairs, we developed a Burp extension that would allow us to do this – simply, the extension allows us to tag specific request/response pairs that relate to confirmed classes of vulnerability, then send those pairs to a configured elasticsearch instance. The extension was initially developed by Corey Arthur based on code from the Logger++ extension (written by Soroush Dalili and Corey Arthur) written in Java. Further work on this was then performed by NCC Group intern Steven Woodhall who rewrote it in Python. A number of improvements were then developed by Daniele Costa including:
- Addition of code to store the request query and request method
- Addition of code to create a UI accessible from the Burp Suite window to set and save settings (i.e. setting the Elastic server host and index, labels for issues)
The plugin allows selecting single or multiple HTTP messages directly from the various burp tools and storing them within elasticsearch using a contextual menu. This menu also includes the “label” to flag the requests with a specific class of vulnerability, such as ‘XSS’, ‘SQLi’, ‘Non-SQLi’, etc.
Data Protection
Picking up from the point above on client consent, we found early on in the design of our architecture that there were issues regarding data protection. The security of our clients and their data is paramount, thus we were not wanting to expose or abuse this data in any way. We realised the following:
- Legacy Burp logs – we only store legacy Burp logs from client engagements when contractually agreed, and even when contractual agreement exists, additional clauses may have been added per engagement on what (if any) additional research-based processing may be performed upon that data. Thus ‘hoovering’ up all legacy Burp logs was not going to be possible and would need confirmation on whether use of the data is permissible for research purposes.
- Crowd-sourced Burp logs from routine engagements – the same issues apply here as with legacy burp logs, in that contractually we may not be able to simply use all captured data for research purposes and may need to be discarding said data at the end of engagements.
- Elasticsearch location – we would need to run and maintain the elasticsearch instance internally to maximise control over its access and protection. While cloud-based solutions in this space would offer a number of benefits in terms of dynamic storage and resilience. we dismissed this option outright for the sake of maintaining full control over a central store of web application data that might contain sensitive data.
- Related to above, the data within web request/response pairs could comprise all manner of sensitive or personal information, depending on the nature and context of the web applications to which the data related. A non-exhaustive list of examples include:
- Authentication credentials and session tokens
- IP addresses and URI schemas relating to different clients
- Personal information (such as address, age, gender, contact details etc.) if the nature of the application were such that it captured and processed such information
- Confirmed vulnerability – where web requests/responses may have been tagged by consultants as vulnerable (e.g. input field vulnerable to SQLi), then in aggregate, a database of known vulnerabilities (possibly not fixed) in real-world applications would pose increased risk and thus demands on its assurance
To address the potential data protection issues identified above, we briefly explored the following:
- Anonymisation/psuedonymisation – the use of such techniques might allow us to remove attribution to organisations, individuals and credentials referenced within web request/response pairs, however the limitations in this field are well understood, in terms of de-anonymisation attacks whereby anonymised data is cross-referenced with other data sources in order to re-identify the original data [3].
- Differential privacy – this topic and technique has certainly been gaining traction in recent years; Google for example have performed research specifically in this domain [4], writing: “Often, the training of models requires large, representative datasets, which may be crowdsourced and contain sensitive information. The models should not expose private information in these datasets. Addressing this goal, we develop new algorithmic techniques for learning and a refined analysis of privacy costs within the framework of differential privacy. “
- Homomorphic encryption – this concept has been around for some time and has been gradually adopted as a working technique in real-world applications [5]. Fundamentally the technique involves performing operations directly over ciphertext without having to decrypt the underlying data, and with the same outcome presenting itself, as if performed over the plaintext version of the data.
While not dismissed outright, our initial understanding here was that such a system might not be optimal since it is dependent on our data exhibiting homomorphic properties, and places high demands on computational requirements. The encryption aspect also means that we would still need to manage the crypto system which would bring with it the usual issues around key management.
Our superficial exploration of the three privacy-enabling mechanisms above revealed that this is a complex problem domain. For our specific research aims with Project Ava, we would need to invest proper time and effort in this area to understand the advantages and limitations of each approach, what effect each approach might have on the utility of the data we would be generating and what training models might be best fit for the project’s purpose. This spun off a separate research project which at the time of writing is ongoing – the research is applicable beyond just Project Ava, and thus warrants its own time and effort in improving our understanding in this domain. As and when we have useful insight from this spin-off research, we shall share this as part of this blog series.
In order to avoid delay to progressing with Project Ava, we settled on the generation of synthetic data for trial and proof of concept. To refine these concepts, we sourced more realistic vulnerable web request/response pairs through a combination of:
- Deliberately vulnerable web applications developed for training purposes – i.e. we have our own internally-developed training resources in addition to open source or freely-available options such as those listed in [6]:
- Bug bounty targets – where we might be able to legitimately engage in bug bounty against specific targets, this could provide another source of necessary web request/response pairs.
On the topic machine-learned models trained on information that may have contained personal data, it is important to consider the obligations around model re-training should a data subject, whose personal data was used as part of the original model’s training, withdraw their consent for data use.
This question or problem here is not exclusive to Project Ava, but is rather pertinent to any ML-based system that has been trained with personal data. In such cases, should any models be re-trained following a subject’s data removal, or is a model deemed to be sufficiently opaque (e.g. a Deep Neural Network with many hidden layers) that it would not be possible to identify the data subject, or the fact the data subject’s data had formed part of the creation of the underlying model?
While the General Data Protection Regulation (GDPR), for example, allows for a risk-based approach, one might think that in relation to the question above, this would simply be a risk management decision. However, the jury appears to be out on this and likely the topic is sufficiently nuanced that it would warrant a case-by-case assessment of the intricacies, rather than a blanket ‘must retrain models upon each consent withdrawal’. Some useful insight on this topic, aligned with interpretation of GDPR can be found in [7].
Power Storage
One final consideration on the architecture and design for Project Ava was power and storage requirements. Our initial reading identified that the training of complex models would require significant computational power, while large volumes of training data would require significant storage. Our choice to keep everything in-house meant that we would not be able to benefit from cloud-based accelerators such as Google’s Tensor Processing Units (TPUs) [8], which can provide up to 11.5 petaflops of performance in a single pod. Because of this, we would be restricted to internal computing power and what might be brought in by way of GPU-based computation.
As for storage, our initial elasticsearch instance was allocated one terabyte of space which would suffice for our prototyping and proofs of concept. However, for any future scaling internally, 1 terabyte would likely exhaust quite quickly given burp logs (depending on target application and size) can commonly grow to between 100s of megabytes to gigabytes in size.
Summary
In this post we identified that quite simple architectures can be developed for projects such as ours, particularly when there is the option for crowd-sourcing the vast amounts of data required for model training. There are many options for creating such architectures entirely in the cloud, and being able to leverage the storage and processing power offered by those environments for scale and speed of computation.
Despite the simplicity of such architectures, privacy requirements mean that a number of additional controls need to be engineered, or at least systems that may process and train on data containing personal information need to be risk-assessed and risk-managed in accordance with privacy requirements from regulations such as GDPR.
While some may see the demands around privacy a barrier to innovation, the reality is such regulation exists to protect everyone involved, from data subjects to data controllers and processors. GDPR has certainly helped us think about privacy by design in our architecture and design of Project Ava, and as such demonstrates its value not just as a regulation, but as a tool in promoting secure systems that minimise the potential of a data breach.
- Part 1 – Understanding the basics and what platforms and frameworks are available
- Part 2 – Going off on a tangent: ML applications in a social engineering capacity
- Part 3 – Understanding existing approaches and attempts
- Part 4 – Architecture, design and challenges
- Part 5 – Development of prototype #1: Exploring semantic relationships in HTTP
- Part 6 – Development of prototype #2: SQLi detection
- Part 7 – Development of prototype #3: Anomaly detection
- Part 8 – Development of prototype #4: Reinforcement learning to find XSS
- Part 9 – An expert system-based approach
- Part 10 – Efficacy demonstration, project conclusion and next steps
References
[1] https://portswigger.net/burp
[2] https://www.elastic.co/
[3] https://www.slideshare.net/NCC_Group/2013-0712-nccgroupdataanonymisationtechnicalaspectsv1-0
[4] https://ai.google/research/pubs/pub45428
[5] https://en.wikipedia.org/wiki/Homomorphic_encryption
[6] https://owasp.org/www-project-vulnerable-web-applications-directory/
[7] https://www.oreilly.com/ideas/how-will-the-gdpr-impact-machine-learning
[8] https://cloud.google.com/tpu/
Written by NCC Group
First published on 12/06/19
