In the fifth blog of the Project Ava series, our research team start to delve into the fun stuff – creating prototypes for applying machine learning to pentesting.
Find out how the team got on with their first prototype below.
Overview
Having understood existing solutions and architected a system for collection of the data necessary for Project Ava, we were now in a position to investigate proofs of concept of ML applied to web application testing.
Rather than attempt a one-size fits all ML approach, we broke down the problem of finding flaws in web applications into more discrete tasks to understand likely successes or gains in each sub category.
Our focus was the OWASP Top 10 [1], with specific emphasis on two common and often critical risk bug classes: Cross-Site Scripting (XSS) and SQL Injection (SQLi). By breaking down each of these into more discrete areas, we planned on investigating which ML method might be best fit for identifying each respective discreet area (e.g. classification, neural network supervised vs. unsupervised) and rapid prototype to obtain results.
Text processing (vectorising, word2vect and neural networks)
Our first exploration was on text processing and specifically, vectorising of words. Given that HTTP request/response pairs are typically textual in nature, we decided to us word2vec [2] to help understand semantic relationships within the HTTP data, under the hypothesis that there would be relationships between say for example certain HTTP error codes and response data containing error information or messages perhaps triggered as a result of malformed data. For example, a HTTP 500 error with accompanying error text of ‘Error in database query’ could be indicative of a SQLi vulnerability triggered by the original web request.
At this stage, we had not yet accumulated real-world or indicative data to experiment with word2vect, and thus were relying on synthetic data quickly generated for testing some of our initial thoughts around semantic relationships in HTTP data. We utilised the python script for this purpose, and split the outputs into training and test data.
The script creates synthetic HTTP data based on various HTTP errors and with mocked-up elements such as randomised tokens and host names. Our intention here was to quickly create a large corpus of example HTTP data to use in our testing. An example synthetic HTTP response generated is shown below:
HTTP/1.1 505 HTTP Version Not Supported
Host: 35vw2objxhw31gs.com
Set-Cookie: hcujcvw=wy23z; Secure; Path=/
X-CSRF-TOKEN: uq4nr82745mt68gesthm3f9ww
Access-Control-Allow-Origin: http://www.35vw2objxhw31gs.com
Content-Length: 29
…
Initial experiments with word2vec and our synthetic data showed promise. We were able to identify semantic relationships that might provide the basis for establishing likelihood of vulnerability from analysis of specific HTTP responses.
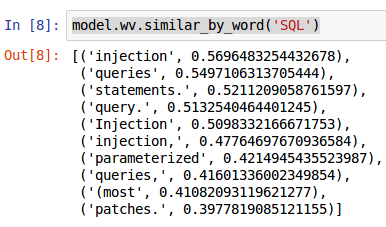
In the example below from our synthetic data, when looking for semantic relationships with the term ‘SQL’, we get keywords that are commonly associated with SQL queries:
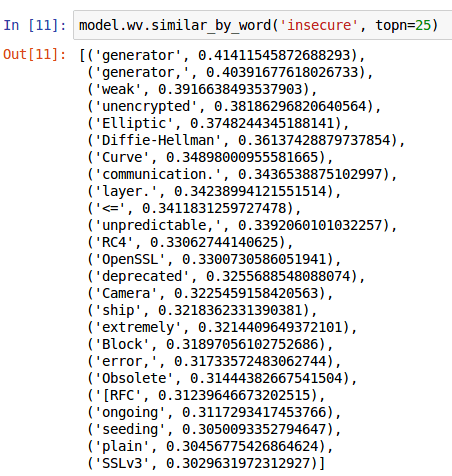
In another example, when requesting the top 25 semantic relationships to the keyword ‘insecure’, we get a number of associations that are commonly synonymous with potential vulnerability when performing web application security testing, such as ‘deprecated’, ‘Obsolete’, ‘plain’, ‘unencrypted’, and ‘weak’.
We then experimented with a number of different model generations and assessed their respective outcomes:
- Artificial Neural Network (ANN) Cosine
- ANN Multiclass, No word2vec (NoW2V) with Long Short Term Memory (LSTM)
- ANN Multiclass
- Convolutional Neural Network (CNN) Binary Classifier NoW2V
- CNN Binary Classifier
- CNN Multiclass NoW2V LSTM
- CNN Multiclass NoW2V
- CNN Multiclass
- Count Vectorizer Binary Classifier
- LTSM Multiclass
- Naïve Bayes Binary Classifier
- Naïve Bayes Multiclass
- Natural Language Toolkit (NLTK) Support Vector Machine (SVM) Linear
- SVM Multiclass
- SVM Multiclass
- TensorFlow LSTM on Web Response
- Vectorizer Multiclass
- Word2vec T-Distrusted Stochastic Neighbour Embedding (TSNE)
- Word2Vec Details Punctuation Case
- Word2Vec Details SQL
- Word2Vec Details Synthetic Overfit
- Word2Vec Details
- Word2Vec Synthetic Overfit
- Word2Vec Synthetic Skipgram
- Word2Vec Synthetic
From these initial experiments the SVM code was found to work best, although we expected the LTSM Recurrent Neural Network (RNN) [3] to have outperformed the SVM, which revealed a potential problem with our initial approach, despite having tried a variety of model sizes and different embedding techniques. At this point we observed:
- The data is naive and therefore the results are skewed, but the core idea appears sound.
- Intuitively, count vectorization will work for classifying vulnerabilities that apply to unique keywords (e.g. insecure cookies). The foundation of this model works because of the count vectorizers and term frequency–inverse document frequency (TF-IDF). While these look good on paper, we assed that they’re problematic.
For example, if a response contained the words “database” and “error” and the data set wasn’t large enough, it’s possible the model would classify the input as SQL injection. For that reason we must incorporate word2vec semantic similarity, preferably with sequence. This is why in a future iteration, we would need to tune an LTSM network with similar embeddings. That way with realistic data sets we could plausibly train the system to accurately classify with real-world data.
This is intuitive when we look at the semantic similarity word2vec provides us, for example: model.wv.similar_by_word(‘Set-Cookie:’)
[(‘Secure;’, 0.9423399567604065),
(‘HttpOnly;’, 0.9014421701431274),
(‘Path=/’, 0.8721677660942078),
(‘301’, 0.8077935576438904),
(‘Permanently’, 0.7919151782989502), This model accurately infers semantic relationships from the synthetic data. It’s easy to determine that the absence of these members in a sequence of input would help identify a particular vulnerability. That is the foundation of our initial approach, which we would build upon in future iterations on this theme. - Complex vulnerability classes should be a unique binary classifier (e.g. a single model for detecting XSS).
- Real-world, classified vulnerable request/response pairs would give us a “security dictionary” to improve these results (honed semantic similarity).
- There is a performance trade-off between complex and simple models that needs to be considered.
- There is much room for improvement, such as applying neural Turing machines [4] and attention networks [5] amongst others.
Our assessment at this point was that the foundation of using NLP to identify vulnerabilities in web responses appeared sound. However, there would be lots of room for improvement. For example, incorporating the original request into the input data. Improvement needed here would include revising state-of-the-art neural NLP techniques, since simply using count vectorizers on their own (which the SVM model does) is flawed.
Likely we would need several thousand examples to train complex models.
Attempts at optimising the LSTM Model
In our next round of research, we further investigated the application of LSTM. We implemented a basic LSTM RNN in tensor flow with a simple embedding layer, fairly typical hyperparameters and design throughout and with training/inferring on a single target at a time.
TensorFlow LSTM HTTP response categoriser
We experimented with an LSTM RNN for detecting security issues within HTTP response data. Our basic workflow was to:
- Tokenize each response, use a word2vec embedding
- Train LSTM on sequences from responses with a binary target for vulnerability presence
Challenges
- Randomness of tokens inside datasets would explode input word vector size (i.e. every response would likely have a random cookie, thus the vocabulary would be infinite). Potentially, we could identify and remove these?
- Because of the above, every new real-world response would contain tokens that aren’t in the word2vec model.
- Currently we are just truncating responses to seq_len.
- Tokenisation is performed with a split on whitespace. A char-rnn would be far slower but possibly better at determining things like XSS payloads?
- Preliminary results
With 10 epochs training, 200 seq_len, 1 layer of 256 LSTM nodes, lr .001, embedding=300; we observed the following accuracy rates:
- Insecure Cookies: poor (and highly variable – even 40 epochs yielded just a 0.217 accuracy)
- Missing CSRF: 100%
- Insecure CORS: 100%
- SQL Injection: 72.6 %
- XSS: 87.2 %
The initial results seemed reasonable, albeit with many caveats, including the fact that we were still using limited and synthetic data. We were now seeing strong accuracy for most bug classes, although curiously, our model wouldn’t converge and was highly unstable for detecting cookie security.
It is likely that we’d face a challenge here since the embedding layer would struggle with unknown tokens, of which cookies are always going to contain variation by virtue of being high entropy random (though we might just expect unknown tokens to be ignored during inference).
We continued trying to optimise the LSTM model to see how it could be improved. Revisiting our goals, we recognised that the detection we were trying to achieve was either finding a fairly easy-to-grep string, such as:
“Set-Cookie: something=something, HttpOnly”
or something very variable and contextual, such as:
“will <script></script>
