Following on from last week’s blog, the eighth instalment in the Project Ava series revisits the theory and approaches of security engineer and researcher, Isao Takaesu, with a focus on XSS.
Overview
In Part 3 of this blog series, one of the existing approaches by others that we found from literature reviews was that of Isao Takaesu [1] as presented at Blackhat Asia 2016. At this stage of our research we decided to revisit some of the theory and approaches from Takaesu, who demonstrated impressive results on intelligently browsing and discovering XSS; albeit on fairly basic web applications.
We wanted to see if we could build on this research, through the creation of PoC ML solutions for generating XSS payloads, as well as by creating a framework for testing and training on those payloads.
Approach
The ML that we used here was a Long Short Term Memory Recurrent Neural Network (LSTM-RNN). One of the biggest issues we faced was writing the algorithm by hand. Most existing libraries and frameworks that we’re aware of use a large set of static data for training and testing, whereas what we wanted to achieve was evaluate dynamically-generated output based on a small set of static inputs against a changing variety of tasks.
We used a static dictionary of HTML and JavaScript and fed this in as the input. The dynamically-generated output of the LSTM-RNN was then broken up into the following segments:
[breakout][opentag][javascript/html5][closetag][breakout]
Each one we evaluated against a set of defined criteria, such as “the opening tag must not contain a ‘/’” etc., whereby we increased the score if the criteria was met. We also increased the score if the payload executed successfully in the framework.
At this stage, our model was quite naïve, yet it produced promising results with a very limited dictionary set. For more challenging XSS such as obfuscation and filter bypass, Takaesu found success by incorporating his model into a genetic algorithm. This was the next step that we tried. We objectified our model and incorporated it into a massively multi-threaded genetic algorithm.
This next phase presented a number of challenges such as how the mutation rate, training rate and evaluation functions would need tweaking to cover the more difficult challenges. The most pressing challenge, however, was uncovering how to submit payloads to websites and receive feedback that we could incorporate in our evaluation. Many frameworks exist to do this – we chose to use Selenium, which, in its “raw” python format, does not support multi-threading, so we decided to use the dockerised selenium-hub [2]. This framework has one “Hub” master container and as many “Node” worker containers as required. The Hub container is then called with requests that it forwards on to its workers to deal with. The Hub may also be called from python. This allowed us to overcome the multi-threading issues and submit payloads to a target web application.
In order to improve the score of each AI bot and incorporate a fuller, more realistic dictionary, we then stepped away from the initial simplistic dictionary. We instead used a subset of all existing HTML and some JavaScript (in a purposefully similar vein to Takaesu’s approach) as the basis for the input dictionary. This caused quite a lot of memory issues as the input layer became massive, which caused the subsequent hidden layers and synapses to overflow and create memory errors. To overcome this, we opted for an approach wherein each candidate was given a reasonably random, reduced subset of this massive dictionary. This meant that instead of relying on each individual to have coverage of all the input material we were relying on the population size to give us coverage. This solved the memory errors but the output strings were not scoring very well.
To try and improve the scoring without increasing the population size we opted for a guided learning approach. We made sure that each random subset of input data contained at least some of the elements we wished to see in the final output. This approach increased the scores by a factor of ten and the output strings looked much more promising.
In order to bootstrap our model we were running very large population sizes, with each one running multiple times. This caused a number of issues.
Firstly, although our consultant laptops are highly spec’d for our daily work, they are no cloud-compute cluster. This meant that running large populations and Docker containers on the same host caused memory and CPU issues. To solve this we moved the test web server to one separate server (as opposed to a VM on the same machine) and the dockerised selenium instances to another high spec’d server. This allowed us to keep our experiments running with large populations so that we could bootstrap an initial model.
The second issue came when we tried to incorporate the selenium tests into every single attempt the bots made at creating a payload. This made the run-time of each experiment go from ten minutes to over ten hours. At the end of some very long runs, we did not see the significant gains we were expecting, so to reduce the run time to something reasonable, we only submitted the best candidate from each generation to the selenium server for testing on the target web server. This made no noticeable change to the scores each generation achieved. We also reduced the run time back from over ten hours to a more reasonable ten minutes. Testing in this way will also have advantages for a real world deployment scenario as it exponentially reduces the number of requests required.
Summary
Although we have a simplistic model, our model that incorporates a genetic algorithm still requires some tweaking before we will have matched Takaesu’s achievements.
We have begun a journey that has taught us a lot about the struggles of creating models and frameworks from scratch and we have overcome many of the pitfalls along the way. With a few more rounds of training and some tweaking of our evaluation criteria, we hope to improve our model so that it will tackle challenges that are more complex.
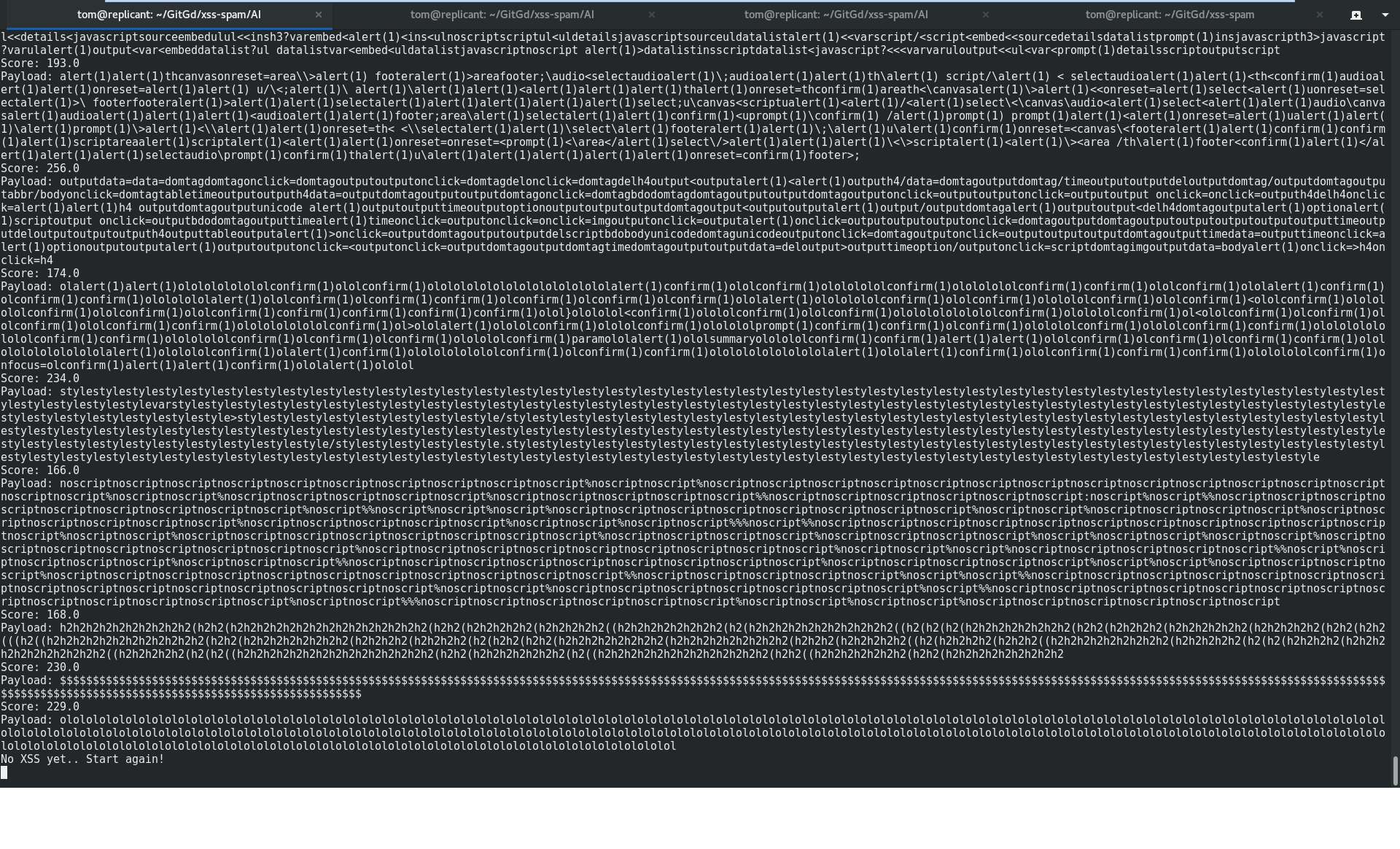
In the meantime, as seen in one of our output runs below, we continue to be trolled by our own creation…
LOL.
- Part 1 – Understanding the basics and what platforms and frameworks are available
- Part 2 – Going off on a tangent: ML applications in a social engineering capacity
- Part 3 – Understanding existing approaches and attempts
- Part 4 – Architecture, design and challenges
- Part 5 – Development of prototype #1: Exploring semantic relationships in HTTP
- Part 6 – Development of prototype #2: SQLi detection
- Part 7 – Development of prototype #3: Anomaly detection
- Part 8 – Development of prototype #4: Reinforcement learning to find XSS
- Part 9 – An expert system-based approach
- Part 10 – Efficacy demonstration, project conclusion and next steps
References
[1] Spider Artificial Intelligence Vulnerability Scanner(SAIVS), Isao Takaesu, 2016, Code Blue Presentation Slides: https://slideshare.net/babaroa/code-blue-2016-method-of-detecting-vulnerability-in-web-apps, Blackhat Asia 2016 Slides: https://www.blackhat.com/docs/asia-16/materials/arsenal/asia-16-Isao-SAIVS-wp.pdf, Demos of it crawling and detecting vulns: https://www.youtube.com/watch?v=aXw3vgXbl1U, https://www.youtube.com/watch?v=N5d9oM0NcM0, MBSD Blog: https://www.mbsd.jp/blog/20160113_2.html, Takaesu’s Twitter: https://twitter.com/bbr_bbq?lang=en, Takaesu’s Github: https://github.com/13o-bbr-bbq/machine_learning_security, Presenting At Code Blue Tokyo 2016 (In Japanese): https://www.youtube.com/watch?v=E-XcDfQlB3U
[2] https://github.com/SeleniumHQ/docker-selenium
Written by NCC Group
First published on 22/06/19
