Abstract
NCC Group’s AI Red Team has had the luxury of evaluating, attacking, and compromising dozens of distinct AI applications. Throughout our tenured history of AI/ML penetration testing, one lesson has become increasingly clear: the IT industry does not understand inherent sources of risk in AI applications. Contrary to popular belief, most impactful AI risks do not originate from the underlying model itself, or even the code used to run AI models. Instead, real, tangible, and painful security vulnerabilities arise from mistaken assumptions about how AI systems interact with conventional application components. And without major architectural changes, all signs point toward security of AI applications growing much, much worse.
But this trajectory is not without hope. NCC Group has compiled several architectural patterns that successfully mitigate AI risks in real deployments. These strategies have been battle-tested and shown to mitigate entire classes of vulnerabilities—that is, when developers implement them properly. By changing the way our engineering teams think about secure AI architectures, businesses can successfully navigate the quagmire of AI security and bring these new threat landscapes under control.
Motivation
Many corporations fail to realize that AI has changed security from a point-and-patch model, where vulnerabilities arise from collections of single-point failures in code, to data-trust models, where the security of a system in motion is only as trustworthy as the data contained within that system. This mistake assumption has led to organizations looking to patch “within” the model by implementing guardrails to (unsuccessfully) mitigate prompt injection instead of designing applications with proper trust segmentation that renders prompt injection irrelevant. The following examples will illuminate several fresh implementations of data-trust approaches that NCC Group has observed reduce real-world risk.
This article does not aim to iterate through all possible secure architectures, but rather to promote examples that implement important defense patterns and evaluate their security strategies. If nothing else, the most important point the author can emphasize is that no secure mechanism exists to expose a model to untrusted data and trust the output of that model at the same time. Stopping prompt injection is the wrong place to look. Rather, with a fresh approach to data-code segmentation and trust-oriented threat modeling, trusted and untrusted execution contexts can be isolated. In other words, by properly architecting AI-integrated applications, concerns like prompt injection can be reduced from overwrought “exploits” to inherent and unimpactful properties of AI applications.
Gatekeeper Pattern
Technology professionals often make the shortsighted assumption that functionality provided to models is all-or-nothing. For example, consider a language model developed to communicate with and execute tasks on behalf of users. Some of these tasks require the model to reference untrusted data, such as text summarization. The naïve approach consists of providing the model with access to any data necessary to fulfill the user’s request. However, this pattern introduces the risk of live data itself manipulating the model’s behavior due to the lack of data-instruction segmentation in LLMs.
Instead, applications can be architected to “gate” protected functionality when models are exposed to untrusted data. Suppose that in the previous example, the “user-facing model” (which may ingest other forms of trusted inputs instead of user data) calls a summary function (typically by outputting a JSON object with the relevant action and parameters), which is processed by backend code. The backend code can then relay the task to a “data-facing” model with access to no sensitive functions (or in the strongest case, no functions at all). This backend-driven gatekeeper pattern enables the user-facing model to perform useful, functional operations when requested by the user, and tasks the untrusted data-facing model to operate on content supplied by potential attackers without introducing the risk of cross-user prompt injection (also called indirect prompt injection).

In other words, this architectural pattern creates two “classes” of instances: one trusted to execute sensitive operations and never exposed to untrusted data, and another to interact with potentially polluted resources. The backend code manages the merging of the instances’ output and returns their response to the user, effectively isolating the two outputs from each other. This paradigm strongly resists horizontal privilege escalation vulnerabilities and is likely the easiest pattern to implement.
Note that this approach does not require two separate foundational models, but rather two distinct sets of capabilities provided to the models at prompt-time.
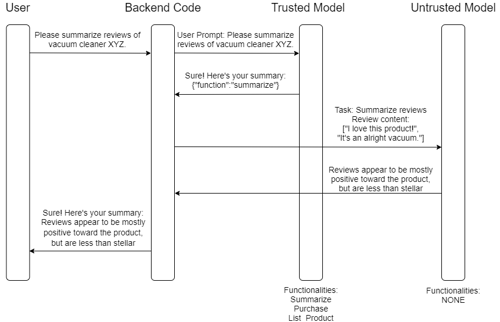
In this example, the user-facing agent is provided the ability to perform function calls that include privileged operations such as account management. A different model instance with no access to privileged operations is called by the backend logic to operate on untrusted data (in this case review summary). The backend merges the output of the two models and provides the final response to the user. By leveraging this gatekeeper architecture, the maximum impact of prompt injection in the content of reviews is limited to an incorrect summary rather than forcing the user to purchase an unwanted product. Of course, in real environments, the complexity of the application codebase will greatly exceed that of this simplified example, but the principle remains the same.
An important gotcha is the ongoing isolation of polluted data. As noted in the previous article, poisoned resources are infectious and can compromise the output from affected models, rendering that model’s responses untrustworthy. Consequently, any output from untrusted “data” models should itself be considered untrusted and masked from future queries to the model. For example, the output of data-facing models may be replaced with a placeholder value such as <masked content summary> when supplied to function-executing models. This content tagging and masking control is critical for models that participate in ongoing and context-drive discussions with users like many LLM agents.
Example Communication Flow For Gatekeeper Architecture
Orchestration Tree Pattern
Consider an architectural pattern in which a primary high-trust model is responsible for selecting downstream instances to accomplish user tasks. In this approach, a user-facing orchestrator model exists to ingest context metadata and user input to determine the appropriate action to take based on the content of the request and delegate the execution of that task to downstream model instances known as leaf nodes. Those leaf nodes are restricted to functionality designated by developers in advance, and the orchestrator model is never exposed to the content of each leaf node’s output (see section Crossing Trust Zones). By maintaining this separation, threat actors cannot poison the behavior of the orchestrator model by injecting malicious content via leaf nodes.

In summary, this approach enables the user to interact with the orchestrator, which reads the content of the user’s request along with a list of recent leaf nodes called during the conversation session. If useful, limited arguments may be provided as well (but not content produced by leaf nodes). The orchestrator determines, based on the content and history, which leaf node is most appropriate to meet the user’s request and delegates the execution to that node. In a sense, this approach is similar to the gatekeeper pattern, but with designated data-facing models for each task the user aims to accomplish, limited to the resources necessary to accomplish that task.
In some instances, it may be helpful to provide intermediary branch nodes that require access to specific data to further assist the user. Branch nodes can access data relevant to and trusted within the context of each individual leaf within its functional domain but may not be trusted to manage leaf nodes that belong to other branches or the root orchestrator. Branch nodes themselves perform the role of micro-orchestrators and determine which leaf most appropriately can manage a user’s request.
Branch nodes are most useful when additional data is required to route a request to a leaf node. For example, consider leaf nodes that account for multiple forms of product management. Rather than manually providing the root orchestrator with instructions on how to route the user’s request to each lead node instance, a branch node may be able to ingest a service description and route the request to the appropriate leaf node. This approach also limits the maximum impact of cross-user prompt injection if a branch node were to be compromised as a result of itself accessing poisoned data or implementation vulnerabilities. Note that this data flow moves in one direction. Branch nodes can receive data from the orchestrator but not leaf nodes. Leaf nodes can receive data from the orchestrator and their parent branches, but not other leaf nodes or other parent branches. Root orchestrators cannot receive data from any other node. In short, branch nodes offer least-privilege assurance when risky information is necessary to complete the user’s objective.
Leaf nodes should each be comprised of one-purpose (or in the strictest case, one-function) model instances, which possess no capabilities beyond their designation. For example, leaf nodes may include chat-only models, weather data interpreters, or even account management systems. In some implementations, leaf nodes may reasonably possess multiple tightly bound functionalities, such as a model to modify the user’s account name, date of birth, and profile description. Most critically, multi-function leaf nodes should always operate on data with the same level of trust. A leaf node with the capacity to access data supplied by the public should not, for example, also be able to modify fields only accessible to the active user.
One primary weakness of both Orchestration Tree and Gatekeeper design patterns is the single point of failure in the root orchestrator model (and its Gatekeeper equivalent, the user-facing model). If a vulnerability exists in the system such that threat actors can control some data point ingested by the orchestrator, those threat actors can compromise any functionality managed by leaf nodes (or functions accessible to user-facing models). This vulnerability would result in a state effectively equivalent to the single-model approach most organizations use today.
A secondary point of consideration is the data consumed by leaf nodes. Even though the orchestrator itself only receives the metadata associated with each request, the application backend must carefully define what data is available to leaf nodes. Due to the untrusted nature of some leaf nodes, supplying data from one leaf node to another can introduce severe risk to the system. Developers who implement exceptions to leaf node isolation policies must carefully ascertain that a source leaf node does not access data that might be considered untrusted by a destination leaf node. Consequently, implementing cross-leaf data movement may result in ongoing technical debt. See the previous article’s section on Authorization Controls for more information on implementing data passing.

State Machine Pattern
A design pattern that has seen success in mature applications is that of a state machine. In a state machine, the application transitions from one mode of operation to another based on the input it receives. For ML models, this process typically involves the model consuming some user input and selecting a new state that can best manage the user’s requirements based on the content of their prompt. The application repeats this process throughout the lifespan of the interaction. In this approach, the application provides no single model with global access to application function calls and instead gates functionality to a limited subset of functions until the user reaches a target state. Functionality is dynamically adjusted according to the user’s location in the application context flow.
For example, consider an agent that starts in a general-purpose conversational state. Once the user indicates an objective (for example, asking about current weather patterns), the application shifts to a state with the functional capacity to meet that objective. However, that the code handling that state should lack access to other protected functions (e.g. a weather pattern reader should not have access to employee payroll) until the user induces the flow to shift to a state capable of managing that request.

State machine architectural patterns usually best fit products with numerous, semi-related functionalities, such as IT support agents. Additionally, because users often change their minds, many agent-based state machines include a path that leads back to the origin in a majority of states. Most critically, state machines in mature environments ensure that agents operate with the fewest functions necessary to address the users’ queries. One limitation of this model is exemplified in user navigation, in which states that lack the functionality necessary to address the user’s goals may lead to frustration. Because users do not know the underlying shape of the state machine, they cannot seamlessly navigate between intended tasks without significant planning and careful implementation on the part of UX designers.
Critically, data-code separation can be achieved by one of three mechanisms. One option is to only leverage user input to process state transitions and to ignore all externally supplied data during the process. For example, a model that reads and summarizes product reviews should be incapable of transitioning to a product purchasing state as a result of prompt injections within the content of the reviews. Rather, the state machine should determine a state transition is needed based on user input alone, with the review summary completely masked from the model when making that determination.
A second option is to enable the model to transition states based on the output of functional operations, but require an isolated and user-managed state for each sensitive operation, which does not receive the outputs of previous states. To leverage the previous example, a malicious review might successfully prompt inject the model to transfer to a purchasing state, but the purchasing state cannot act without additional input from the user, who likely will not confirm an unwanted purchase (such as via Human-In-The-Loop), and itself is not exposed to the output of the previous malicious state.
The final option is to consider each state an independent orchestrator that follows an Orchestration Tree pattern as explored in the previous section.
A primary weakness of state machines is that in complex systems, they can become unwieldy and difficult to debug, and state machines may come at the cost of flexibility. State machine patterns are likely most useful in systems with known and rigid requirements or user flows.

Crossing Trust Zones
Few mechanisms exist to pass unstructured textual data across trust zones due to the principle of infectious data pollution in LLM inputs/outputs. However, developers do possess architectural tools that can mitigate the risk of prompt injection from untrusted to trusted models.
LLMs excel at processing unstructured data. However, the components that consume LLM output rarely process unstructured data themselves (with the notable exception of users, who are not at serious risk of prompt injection). Accordingly, the simplest mechanism to pass data from an untrusted model to a trusted model is to convert the data to a safe type.
For example, consider a low-trust model in a poorly configured environment that reads the description of a product and passes a summary of the description to a model within a trusted execution zone (such as an orchestrator or user-facing model). Threat actors can generate a malicious product description that influences the trusted model. If instead, the data-facing model were to produce structured, non-interpretive data necessary to accomplish the intended task, that data might be safely passed to trusted models.
If, in this example, the purpose of the description summary were intended to produce a suggested quantity for the user to purchase, the quantity integer can be considered a “safe” value to pass from an untrusted model through the backend code to a trusted model. In this case, the maximum impact of a poisoned model description is limited to an incorrect suggested purchase quantity, which should itself be mitigated by user-based Human-In-The-Loop verification.
Suppose further that sensitive user information were required to determine the appropriate purchase quantity. In this example, that data point can safely be passed to the untrusted model under the explicit condition that the untrusted model has no access to write operations, according to the principle of least privilege. A model with access to sensitive user information, untrusted data, and write functionality is overscoped and vulnerable to exfiltration attacks.
Similar to data type conversions, LLMs can select pre-defined elements from lists, which are passed to trusted models via backend code. These lists may even include suggested function calls to be executed by upstream agent. Other “data filters” can be selected based on their appropriateness for the project in question. Most critically, these filters must be defined and validated by immutable backend code and not by the model itself. Otherwise, models could submit prompt injections upstream that claim to be trusted data types and poison high-trust zones. Additionally, LLMs should never be used to validate the output of LLMs due to their own susceptibility to injection and manipulation attacks.

Conclusion
Although the above examples are far from exhaustive, they exist to provide samples of safely implemented architectures that integrate AI components. Simplified versions of these patterns may also meet business requirements, but organizations should verify with trusted security partners that such simplifications do not introduce new risks or vulnerabilities. By designing for dynamic least privilege and carefully managing data passed between trust zones, AI technologies can be harnessed and embraced rather than feared. But the onus lies on corporations, developers, and security professionals to enforce AI security-by-design and to avoid the vulnerability Wild West that far too often arises in the wake of novel technologies.