This is the first blog post in a new code-centric series about selected optimizations found in pairing-based cryptography. Pairing operations are foundational to the BLS Signatures [1] central to Ethereum 2.0, zero-knowledge arguments central to Zcash and Filecoin [2], and a wide variety of other emerging applications. A prior blog series implemented the entire pairing operation from start to finish in roughly 200 lines of straightforward Haskell. This series will dive deeply into individual optimizations that drive raw performance in more operational systems. This post will cover modular Montgomery arithmetic [3] from start to finish, including context, alternatives, theory, and practical working code in Rust running 9X faster than a generic Big Integer implementation. The context and alternatives presented involve common techniques relying on Solinas primes, why pairing curves require more sophisticated thinking and an intermediate look at Barrett reduction. The next blog post will further optimize the (relatively) heavyweight Montgomery multiplication routine in bare-metal x86-64 assembly language.
Overview
Pairing-based cryptography [4] is fascinating because it utilizes such a wide variety of concepts, algorithms, techniques and optimizations. For reference, the big picture can be reviewed in the three blog posts listed below. This post will focus on modular Montgomery arithmetic in finite fields as used by the pairing operations underpinning BLS Signatures.
- Pairing over BLS12-381, Part 1: Fields
- Pairing over BLS12-381, Part 2: Curves
- Pairing over BLS12-381, Part 3: Pairing!
All of these blog posts complement existing theoretical resources by placing a strong emphasis on actual working code. While the earlier blogs implemented everything in high-level Haskell, the focus now shifts towards performance-oriented Rust and even some assembly code. The source code for this series of blog posts is available at https://github.com/nccgroup/pairing to facilitate your experimentation.
For our specific purposes, a finite field is a set of integers from 0 to N − 1, where N is our field prime modulus, along with two operations (addition and multiplication modulo N) satisfying a few properties:
- Closure: an operation on two elements of the set results in another element of the set.
- Associativity and commutativity; multiplication is distributive over addition.
- The existence of additive and multiplicative identity elements.
- The existence of an additive inverse for all elements and a multiplicative inverse for all non-zero elements.
Note that the narrow definition above intentionally does not cover all types of finite fields.
Data Types
Elliptic curve and pairing-based cryptography operates with extremely large numbers, e.g., 2381 and beyond. The earlier Haskell code used the built-in arbitrary-precision Integer type that included support for the modulo operator. Since the BLS12-381 prime field modulus N is a fixed-sized value and the field arithmetic operations are nicely constrained, there is a significant opportunity to optimize for performance, though the modular reduction operation presents a formidable obstacle. The number structure W6x64 shown below consists of six 64-bit unsigned integer limbs that each match the natural data operand size of modern phone, desktop and server CPU architectures. This allows for enough overall space to represent unsigned integers up to 2384 − 1. Also shown below is the exact prime field modulus N value for BLS12-381 [5]. All of this code is available in the repository at https://github.com/nccgroup/pairing/blob/main/mont1/src/arith.rs.
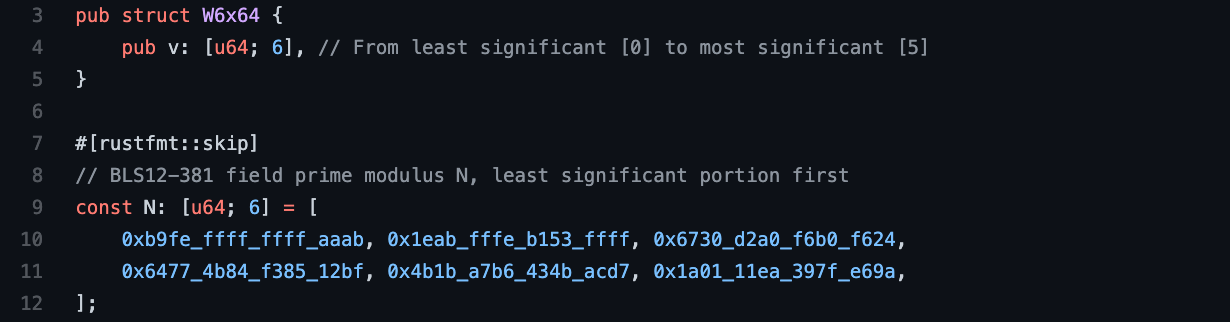
While the W6x64 data structure above clearly provides more range than minimally necessary, the functionality developed in this blog post will assume that all inputs and outputs fall between 0 and N − 1. A subsequent blog post will analyze the functionality under relaxed range constraints and highlight a few related performance tricks.
Addition and Subtraction
Let’s immediately jump into implementing arithmetic functions, starting with addition and subtraction. Later we will realize that these functions also work perfectly for operands in Montgomery form. Conceptually, these functions contain the basic arithmetic operation followed by a modular reduction to place the final result into the proper range of the finite field set. Ordinarily, the modulo operator returns the remainder after dividing by the modulus N, which implies a very expensive division operation behind the scenes that can greatly impact performance and is thus avoided whenever possible. When a value is within the range of our finite field set, it is said to be properly reduced.
For addition, after adding two properly reduced elements into an intermediate sum, there are only two possible cases to handle for the follow-on modular reduction step: A) the intermediate sum value is already properly reduced, or B) the intermediate sum value is not properly reduced, but subtracting the modulus N once from the intermediate sum value produces a properly reduced final result. The correct case can be determined by running a trial subtraction of the modulus N from the intermediate sum to see if there is an overflow (towards negative infinity) – a borrow returned from the most significant subtraction indicates that the intermediate sum was already properly reduced. The code below sums the operands, performs a trial subtraction of the modulus N, and uses the final borrow to select the proper case to return. The first loop on lines 19-24 encloses a single full-addition [6] implemented as two overflowing (half) addition operations. Note that the wrapping_neg() function [7] on line 35 converts a borrow of 1 into u64::MAX which is then used as a selection mask in the final multiplexer implemented with AND-OR Boolean logic.

The above code is written in such a way that the execution path and memory access patterns do not depend upon the data values, though the compiler cannot be trusted to respect this. In fact, even the processor’s micro-architecture may introduce timing variations. Nonetheless, this approach strives towards a constant-time [8] operation to minimize/prevent timing side-channels that are generally present in arbitrary-width Integer libraries. These side-channels are frequently in the news [9] and will be discussed further in subsequent blog posts. In any event, the above code requires 6 sequential full-addition operations, 6 sequential subtraction operations and some Boolean logic that can be partially run in parallel. An expensive division operation has been avoided.
For subtraction, a similar approach to modular reduction is possible. After subtracting two properly reduced elements to calculate an intermediate difference, there are only two possible cases to handle for the follow-on modular reduction step: A) the intermediate difference value is already properly reduced, or B) the initial subtraction has caused an overflow towards negative infinity that needs to be corrected. This correction entails simply nudging an intermediate difference value that overflowed the native data size (six by 64-bits) into one that instead overflows the modulus N value. The correction consists of another round of subtractions involving the difference between N and 2384. The code shown below performs the initial subtraction and uses the last borrow on the intermediate difference value to indicate overflow. That borrow is converted to a mask on the correction constant for the second operand of another round of subtractions on line 65. The correction constant shown below is simply the difference between the native data size of all limbs less the modulus N.

Note that the full subtraction enclosed in the first loop is implemented as two overflowing (towards negative infinity) subtractions, similar to the full-addition seen earlier. The second loop can be written with a single overflowing subtraction because adding the borrow bit to the fixed second operand can never overflow. The above code is also written such that the execution path and memory access patterns do not depend upon input data values. The code requires 12 sequential subtraction operations along with some Boolean logic to select a proper correction value. An expensive division operation has been avoided again.
Avoiding Division
So far, avoiding the expensive division operation implicit to the modulo operator was enabled by the realization that the relatively-narrow intermediate results from basic addition and subtraction operations can be corrected in a much simpler and faster fashion.
Things get very interesting when considering multiplication, as pairing operations can potentially involve 10-100 million field element multiplication operations that consume a large proportion of the overall running time. Imagine multiplying two large n-digit decimal numbers by hand. The naive process would involve n2 single-to-double digit multiplications with carry-propagating additions to work out n partial products, followed by even more carry-propagating additions to sum the partial products into a 2n-digit wide intermediate product. For operands with six 64-bit limbs, as this blog series utilizes, this requires 36 single-to-double precision multiplications resulting in a twelve 64-bit limb intermediate product as shown in the figure below. Quite a lot of additions are needed to collect all the partial product terms into the single intermediate product. At the end, the double-width intermediate product faces a far more challenging modular reduction, potentially involving an extremely expensive division, to reduce this down into the range of the finite field set (elements between 0 and N − 1 in six limbs).

Solinas Primes
In fact, the motivation to avoid this expensive division has encouraged many to choose a modulus in such a way as to enable interesting tricks for modular reduction. For example, the NIST P-521 curve [10] utilizes a Solinas [11] prime modulus N of 2521 − 1 such that any integer less than N2 can be expressed as A = A1 · 2521 + A0. Since 2521 ≡ 1 mod N, the wide intermediate result is easily reduced to the final result = (A1 + A0) mod N. This is a basic alignment then modular addition operation, which the Rust code above demonstrates to be quite simple and fast!
Similarly, the prime modulus N chosen for the NIST P-224 curve is 2224 − 296 + 1. For this curve, a comparable and fast modular reduction scheme is obtained by considering the double-wide intermediate product A to consist of seven 64-bit limbs Ai (with two of them broken out into 32-bit HIGH and LOW portions) and following the recipe below to quickly achieve a fully reduced result:

Using insight from our earlier Rust code for the modular addition and subtraction functions, the above approach would require approximately 8 single-precision full-addition operations, 24 single-precision subtraction operations, and their surrounding Boolean logic. The strategy of using Solinas (or similar) primes is fantastic for performance and thus is the default choice when the freedom of choosing primes exists.
Unfortunately, curves and fields suitable for pairing have a large number of constraints that remove the freedom to choose these attractive primes. These constraints involve the target security level of the base field and curve, the embedding degree of the extension field, the desired twists, and the target pairing algorithm. So the BLS12-381 field prime modulus N hard-coded into the Rust code at the top of this post has no special form nor enables any silver-bullet tricks. From this point forward performance will be estimated by counting single-to-double precision multiplication operations (rather than addition and subtraction) as these are the most time-consuming in terms of both latency and reciprocal of throughput, and thus more representative of expected performance. As an ironic aside, in the next blog post the fact that the additions have more carry-related dependencies will actually become the source of a decisive optimization.
Barrett Reduction
Before moving on to the main topic of Montgomery arithmetic (and reduction), let’s touch on another popular modular reduction method for arbitrary primes – Barrett reduction [12]. This technique is most useful when the modulus is fixed, as ours is, because it requires the calculation of a special constant that can be hard-coded into our program. The method stems from first approximating the quotient q̃ of our intermediate result x divided by our modulus N, and using that quotient approximation to make an estimate of the remainder r̃:
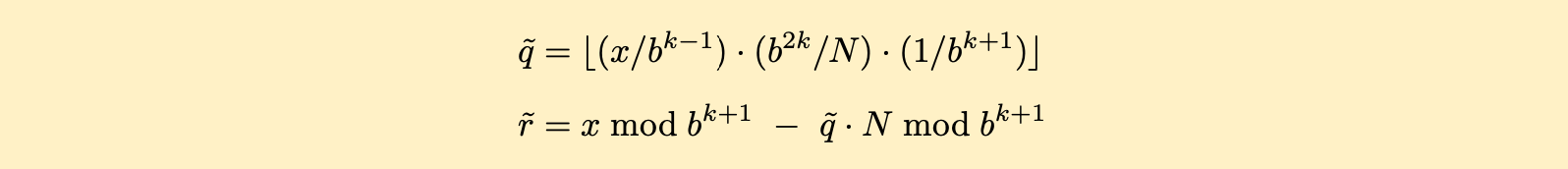
Squinting just right at the first equation where b is our base (264 or limb size) and k is our number of limbs (6), we can almost see all the b terms canceling out of the numerator and denominator, leaving us with a quotient of x/N . In reality, the leftmost division is simply a shift right that removes some less significant limbs from x, which is then multiplied by our special precomputed constant in the center, and that result is again shifted right to leave us with an approximated quotient. The second equation uses the approximated quotient to estimate the remainder, on which a few subtractive correction steps can be applied similar to those described earlier. A careful accounting reveals that while these two equations appear to require two full k + 1 width limb multiplications with each involving (k + 1)2 single-to-double precision operations, it can in fact be optimized to require k2 + 4k + 2 or 62 single-to-double precision multiplication operations for our six-limb configuration. This modular reduction overhead is on top of the 36 single-to-double precision multiplication operations required for the intermediate product for a total of 98 single-to-double precision multiplication operations along with all the follow-on summations. Nice, but there remains an opportunity to increase performance further.
Montgomery Arithmetic
Conquering Montgomery arithmetic will be done in three large figurative leaps. First, a special constant will be chosen and then some relatively straightforward functionality will be quickly taken off the table. Second, the theory underpinning the REDC algorithm that makes Montgomery reduction work will be reviewed. Finally, that theory will be put into practice by implementing an integrated multiplication and modular reduction function in Rust.
Conversion, Addition and Subtraction
Our first large leap into Montgomery arithmetic involves converting normal operands into Montgomery form and back. A special value R is chosen that is minimally larger than the prime modulus N, has no common factors with it, and nicely aligns with the size of our operand data structure – in this blog series involving BLS12-381, choosing R = 2384 is natural as it maps to our data structure containing six 64-bit limbs. Ignore the strange feeling associated with the fact that R is larger than N.
Starting with a normal form operand a, the conversion to Montgomery form involves a simple modular multiplication to get ã = a · R mod N. The overhead tilde represents a value in Montgomery form. To convert the Montgomery form operand ã back to normal form, another simple modular multiplication is performed to get a = ã · R−1 mod N . Note that modular addition and subtraction are independent of form and work exactly as before. As illustrated below, the conversion from normal to Montgomery form is shown on the left, standard modular addition and subtraction definitions are shown in the center, and the conversion from Montgomery form back to normal form is shown on the right.
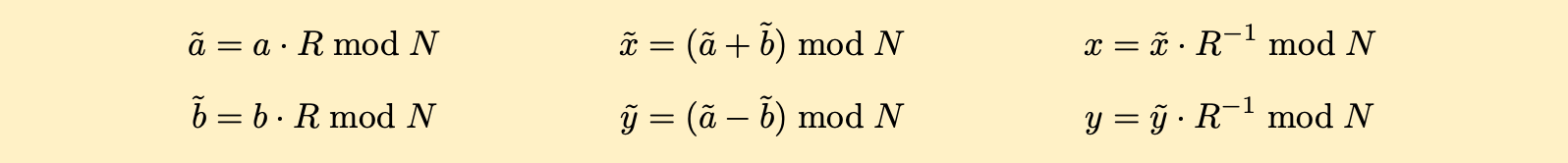
This means that the addition and subtraction functions developed earlier in Rust work unchanged and can be taken off the table. Obviously, the overhead associated with both conversion steps must be somehow compensated for across the intervening operations in order for the Montgomery approach to be worthwhile/beneficial.
Imagine a normal multiplication of two Montgomery-form operands ã and b̃ that gives an intermediate (wide) product of T = ã · b̃ mod N , which also equals a · b · R2 mod N. It is clear that arriving at our desired result in Montgomery form requires one more step: z̃ = T · R−1 mod N. This last step is known as Montgomery reduction or REDC. Therefore, the overall function that needs to be implemented in Rust is mont_mul(ã, b̃) = ã · b̃ · R−1 mod N.
A nice trick with Montgomery arithmetic is that the implementation of a single function, the mont_mul() function [13], allows us to convert to and from Montgomery representation based on the function arguments. Specifically, to convert a normal form operand a to a Montgomery form operand ã, the calculation ã = mont_mul(a, R2) = a · R2 · R−1 mod N = a · R mod N is run. To convert a Montgomery form operand ã to a normal form operand a, the calculation a = mont_mul(ã, 1) = ã · 1 · R−1 mod N = ã · R−1 mod N is run. This is easily implemented below in Rust.

Our first large leap is now complete. The special constant R has been carefully chosen, operand conversions between normal and Montgomery form have been defined in both directions, and performance-oriented Rust implementations for addition, subtraction and both conversions are in hand.
Montgomery Reduction REDC
Our second large leap starts with the double-width intermediate product T = ã · b̃, which comes from the basic multiplication operation requiring 36 single-to-double precision multiplication operations referred to earlier and shown in the diagram further above. The primary goal is to understand the REDC Montgomery reduction algorithm resulting in T · R−1 mod N. The math for this section gets a bit involved, so the key equations are collected together and numbered near the end, and the text notes the corresponding equation reference (eqns 1-8) inline – hopefully this makes the theory even more digestible.
Notice that adding a multiple of our modulus N to T will not change its final residue result modulo N. If a sufficient multiple m of our modulus N were added to the intermediate result T, e.g. T + m · N (eqn 6), the sum would eventually become a multiple of R too. At that point, dividing by R (eqn 7) – which is a simple and inexpensive right shift – brings the magnitude of our value down very close to the modulus N . This can be done because R−1 mod N exists and cancels R; note that a clean quotient without a remainder comes from the fact that a multiple of R contains no information in the least significant 384 bits. This would be nearly a full modular reduction without any expensive division operations. The challenge is to calculate how many multiples m of the modulus N are needed to make T + m · N also a multiple of R (eqn 6). First, an interesting relationship between multiples of R and N must be calculated.
Since R and N have no common factors, Bézout’s identity [14] tells us that there exists integers Rp and Np such that R · Rp + N · Np = 1 (eqn 1). One of these integers will be negative. The extended Euclidean algorithm in Python below can be used to work out these integers. Lines 3-16 of the Python code below do exactly this. This code only needs to be run once during development to calculate the hard-coded constant that will be used in the Rust code.
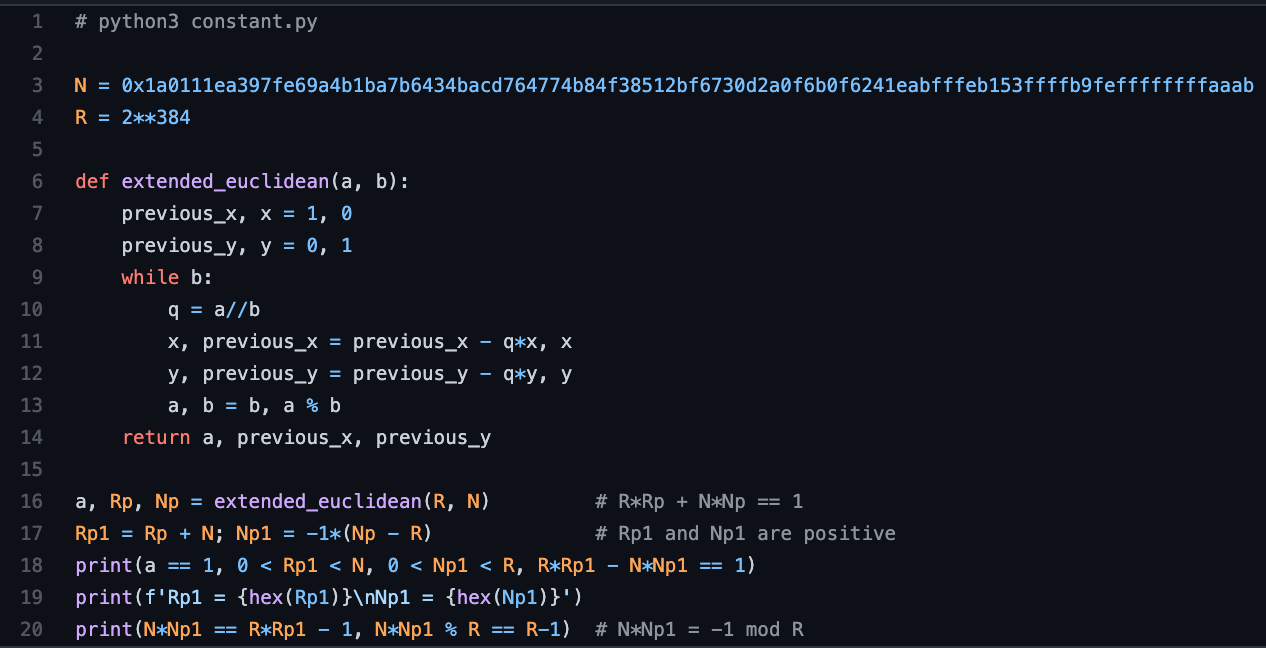
The results that the extended Euclidean algorithm returns can be adapted to find two related integers (on line 17) Rp1 and Np1 such that R · Rp1 − N · Np1 = 1 (eqn 2). With a little rearrangement, it becomes clear that N · Np1 ≡ −1 mod R (eqn 4). Note that the tests printed on lines 18 and 20 all evaluate to true, and indicate that both integers Np1 and Rp1 are positive and less than the original R and N respectively (eqn 3).
The last calculation above (eqn 4) tells us that Np1 multiples of our modulus N are congruent to −1 mod R. Thus, if T mod R ≡ x, then T · Np1 · N mod R ≡ −x and the residues cancel when summed: T + T · N · Np1 ≡ 0 mod R (eqn 6). So the multiple of the modulus N that we have been looking for is m = T · Np1. At this point, the sum T + m · N can be divided by R (eqn 7), which is an inexpensive right shift, to get an estimate of the reduced result U. To recap:
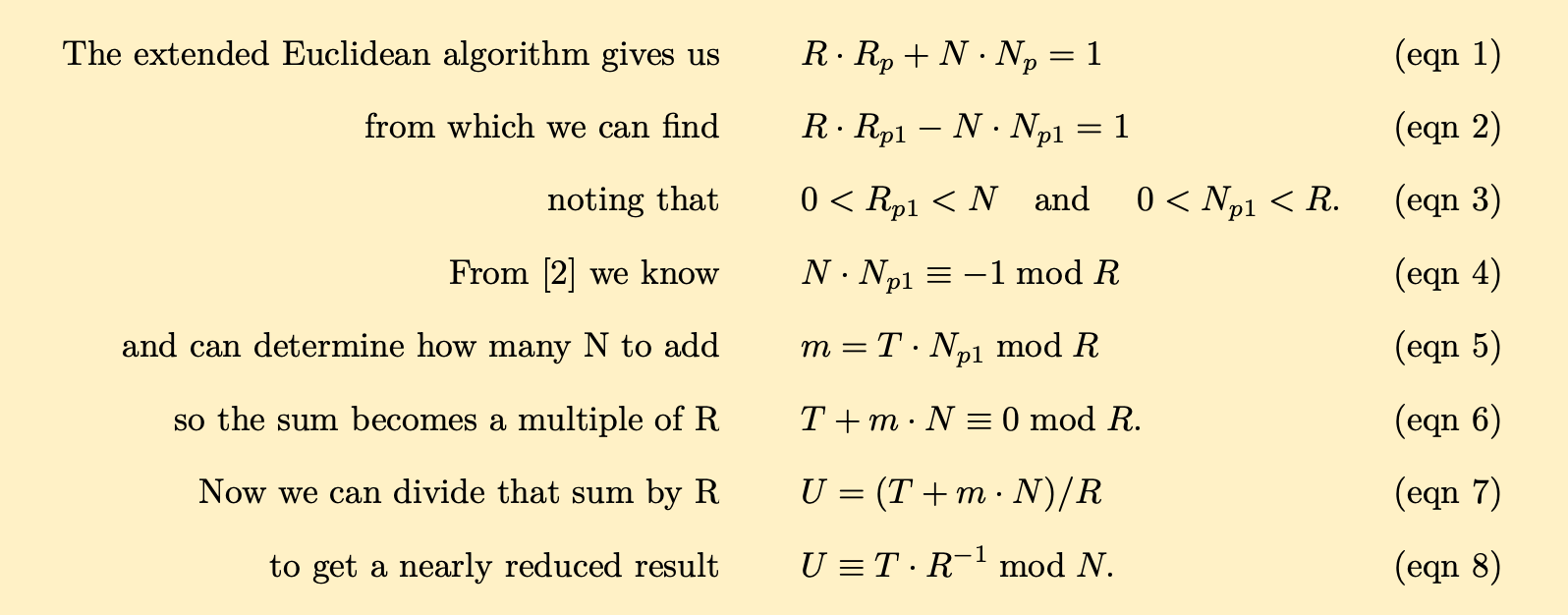
As with addition and subtraction, a careful accounting of the values’ maximum magnitudes presents only two possible cases to handle for the correct result: A) U is already properly reduced, or B) U is not properly reduced, but subtracting the modulus N once will deliver a properly reduced result. This correction step matches what was done for the subtraction routine in Rust. The overall process delivers T · R−1 mod N without an expensive division operation!
The above theory completes our second leap. At first glance, it appears that the T · Np1 mod R term in (eqn 5) and m · N term in (eqn 7) will require two full-precision multiplications, so the REDC algorithm may not be all that attractive in the end. However, as will be seen next, implementing the code using limbs will allow us to convert one of the full-precision multiplication operations into roughly one single-to-double precision multiplication. At that point, a multiplication integrated with Montgomery reduction will be faster than a multiplication followed by Barrett reduction.
Montgomery Multiplication and Reduction in Rust
The third and final large leap involves implementing an integrated Montgomery multiplication and modular reduction operation in Rust. This will make use of exactly the same six by 64-bit limb data structure in the function signature as the other Rust routines. Since the choice of R aligns nicely with the multiple of limbs within our data structure, and R is co-prime to the least significant limb of N, the code works [15] with Np1 mod 264 rather than the full width Np1.
There are multiple ways of integrating the calculation of partial products, their modular reduction and summation [16] . Much of the preceding text visualizes the entire multiplication operation fully separate from the following modular reduction operation for simplicity. Alternatively, several approaches involve fine-grained integration of the two operations on an individual single-to-double multiplication basis. Here we will focus on the approach of working with complete partial products known as CIOS or Coarsely Integrated Operand Scanning.
The code below contains an outer loop starting on line 106 to calculate and sum each partial product. Each partial product is calculated by a first inner loop for multiplication and summation starting on line 108, followed by a second inner loop to perform the modular reduction starting on line 120. These two inner loops are separated by the calculation of a 64-bit m value using N_PRIME = Np1 mod 264.
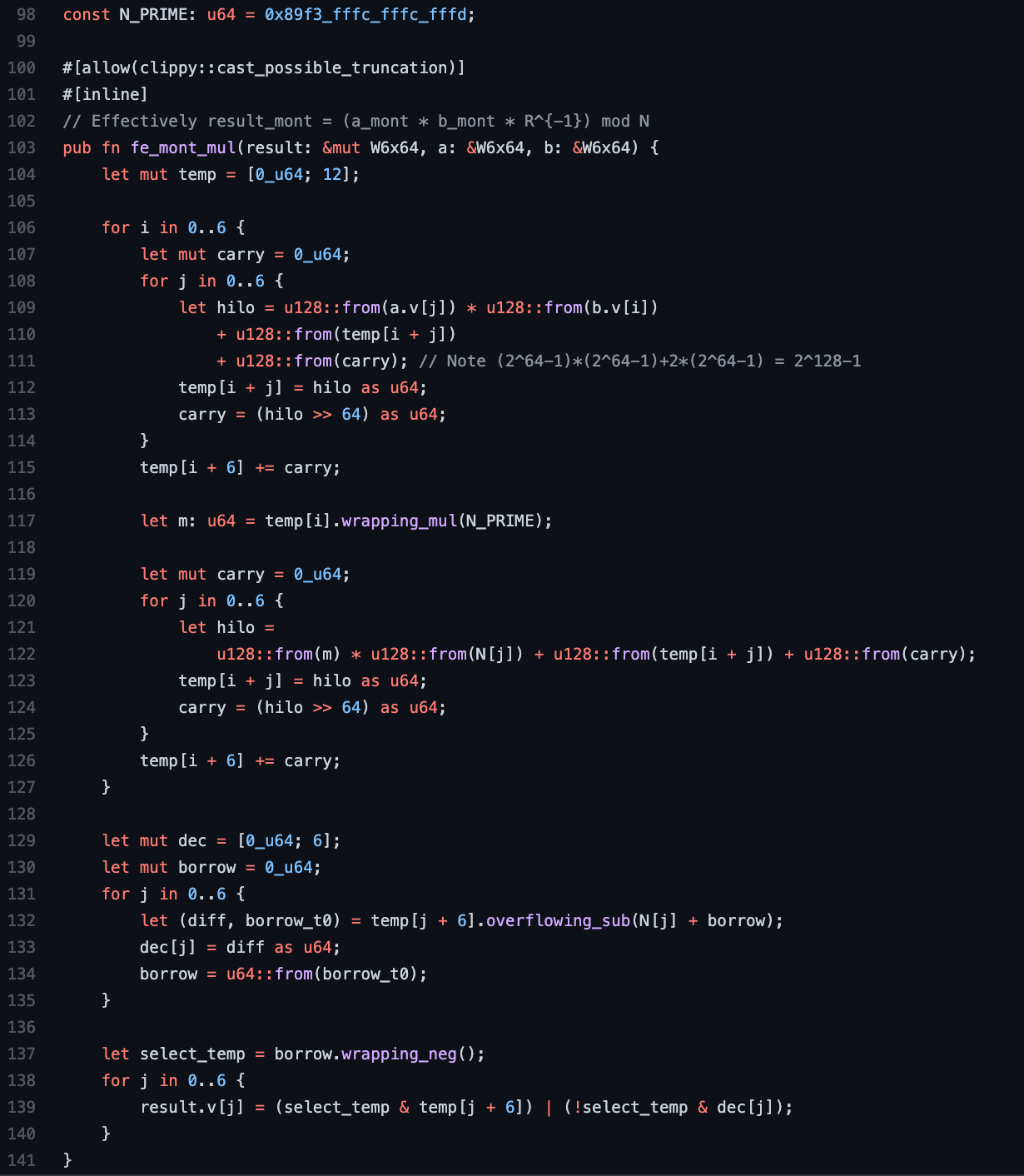
Lines 129-140 implement a trial subtraction and selection of the correct result, just like in our addition routine. A careful count finds a total of 6 * (6 + 1 + 6) = 78 single-to-double precision multiplication operations, which is a win over Barrett reduction. As before, there is no expensive division operation.
Benchmarks
All of the above theory and implementation has introduced considerable complexity. So it is natural to consider and measure the benefits – in this case we are looking for a relative figure-of-merit rather than absolute precision.
The repository contains a benchmarking harness [17] that compares A) modular multiplication implemented with Rust’s arbitrary precision BigUint library, and B) the integrated Montgomery multiplication and modular reduction code shown above. Each operation is run 1000 times, so the absolute timing results reported below need to be divided by 1000 to best approximate the reality of a single operation. The results reported below are returned from the cargo bench command.
The throughput of the custom Montgomery multiplication and modular reduction code is 9X greater than the BigUint code. As shown above, custom assembly can achieve a 16X throughput improvement over the BigUint baseline and will be described in the next blog post.
What have we learned?
This blog post has covered quite a bit of theory related to general modular reduction techniques. Pairing-based cryptography does not have the luxury of selecting ‘attractive primes’ to take advantage of simplified and performance-oriented modular reduction strategies like the NIST (and many other) curves do. While Barrett reduction provides an attractive alternative and is relatively straightforward to describe and understand, Montgomery methods hold the final advantage. Essentially all performance-optimized pairing-based cryptography libraries use these techniques.
We have implemented practical wide-precision addition, subtraction, multiplication and conversion routines that include modular reduction and outperform Rust’s BigUint by more than 9X. The code is available at https://github.com/nccgroup/pairing/blob/main/mont1/src/arith.rs for further experimentation.
What’s next?
The benchmark data above indicates there is even more performance available with hand-coded assembly. The very next blog post will develop a hand-optimized x86-64 implementation of the multiplication and modular reduction routine from this post. Future posts will begin to look at additional curve-related optimizations. Stay tuned!
Thank you team
The author would like to thank Parnian Alimi, Paul Bottinelli and Thomas Pornin for detailed review and feedback. The author is responsible for all remaining issues.
References
[1]: BLS Signatures draft-irtf-cfrg-bls-signature-04 https://datatracker.ietf.org/doc/html/draft-irtf-cfrg-bls-signature-04
[2]: A crate for using pairing-friendly elliptic curves https://github.com/filecoin-project/paired
[3]: Montgomery Arithmetic from a Software Perspective https://eprint.iacr.org/2017/1057.pdf
[4]: Thesis: On the Implementation of Pairing-Based Cryptosystems https://crypto.stanford.edu/pbc/thesis.pdf
[5]: Pairing-Friendly Curves draft-irtf-cfrg-pairing-friendly-curves-09 https://datatracker.ietf.org/doc/html/draft-irtf-cfrg-pairing-friendly-curves-09
[6]: Full adder https://en.wikipedia.org/wiki/Adder_(electronics)#Full_adder
[7]: Rust documentation, wrapping (modular) negation https://doc.rust-lang.org/std/primitive.u64.html#method.wrapping_neg
[7]: Why Constant-Time Crypto? https://www.bearssl.org/constanttime.html
[8]: New Spectre attack once again sends Intel and AMD scrambling for a fix https://arstechnica.com/gadgets/2021/05/new-spectre-attack-once-again-sends-intel-and-amd-scrambling-for-a-fix/
[9]: D.2.5 Curve P-521 https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.186-4.pdf
[10]: Solinas primes https://en.wikipedia.org/wiki/Solinas_prime
[11]: Barrett reduction https://en.wikipedia.org/wiki/Barrett_reduction
[12]: Alfred J. Menezes, Scott A. Vanstone, and Paul C. Van Oorschot. 1996. Handbook of Applied Cryptography (1st. ed.). CRC Press, Inc., USA. Section 14.3.2 https://cacr.uwaterloo.ca/hac/about/chap14.pdf
[13]: Montgomery modular multiplication https://en.wikipedia.org/wiki/Montgomery_modular_multiplication
[14]: Bézout’s identity https://en.wikipedia.org/wiki/B%C3%A9zout%27s_identity
[15]: Analyzing and Comparing Montgomery Multiplication Algorithms https://www.microsoft.com/en-us/research/wp-content/uploads/1996/01/j37acmon.pdf
[16]: Benchmarking code https://github.com/nccgroup/pairing/blob/main/mont1/src/bench.rs
