Istio is a service mesh, which, in general, exist as a compliment to container orchestrators (e.g. Kubernetes) in order to provide additional, service-centric features surrounding traffic management, security, and observability. Istio is arguably the most popular service mesh (using GitHub stars as a metric). This blog post assumes working familiarity with Kubernetes and microservices, but does not assume deep familiarity with Istio.
This blog post takes a critical look at a subset of Istio’s features. In particular, we will focus on Istio’s security features that are used to control services’ network interactions: restricting egress traffic, restricting ingress traffic, and requiring a TLS client certificate from a service’s callers (i.e. mutual TLS). We will walk through lab-based examples drawn from Istio’s documentation in order to concretely illustrate the limits of each of these features, possible misconfigurations, and what can be done to ensure operators’ intended security goals are met. For example, this post highlights an aspect of Istio’s AuthorizationPolicy object whose behavior is changing in the forthcoming Istio 1.5 release, which will allow operators to express mesh-level authorization rules that cannot be overridden at the namespace or service-level.
Table of Contents
Preliminaries
Istio Primer
Before digging into these security-related features, a brief overview of Istio’s internals is required. The figure below, which is from Istio’s documentation, depicts Istio’s core components:

The main takeaway from the figure above is that Istio is separated into two logical pieces: the control plane and the data plane, which exist as Kubernetes objects (e.g. Pods).
The data plane, which is where this blog post will focus, is made up of services (i.e. applications) deployed to the service mesh. Istio joins services to the data plane at deploy-time by injecting a sidecar proxy (istio-proxy) and init container (istio-init), which are separate containers within a service’s Pod, in addition to a service’s container that actually executes the service’s application code. Pods in Kubernetes are comprised of one or more containers that share Linux namespaces, such as the network namespace. Init containers are containers that run and exit before others in the Pod. In order to “hook” network traffic coming in to or out of a service, istio-init uses a Bash script and the CAP_NET_ADMIN capability to set iptables rules in the service’s Pod’s network namespace, such that incoming and outgoing TCP traffic is forwarded to the istio-proxy container. The forthcoming Istio 1.5 release will switch to a Golang-based iptables setup program, rather than the current Bash one.
The istio-proxy container is based on the Envoy proxy, and it communicates with the control plane, which programs the proxy at runtime to realize various Istio features, such as path-level authorization rules (an AuthorizationPolicy), egress restrictions, ensuring those calling the proxy’s associated service present a TLS client certificate, etc.
The control plane comprises the core components of Istio itself, which primarily exist to coordinate and configure the istio-proxy sidecars that accompany each application container (i.e. the data plane). For example, Istio’s Pilot component realizes the specific Envoy configurations for the istio-proxy sidecars, and propagates this to the relevant sidecars. See the following figure from Istio’s documentation:

Reference Cluster
This post uses a local Istio environment for its examples, by way of minikube, a VM-based tool for creating local Kubernetes clusters. The instructions below can be used by readers who wish to follow along with interactive examples.
All installation instructions assume an Ubuntu 18.04.4 LTS workstation capable of virtualization, from which the KVM-based minikube driver is used, though minikube works with other operating systems and hypervisors, and so do the command line tools needed for Kubernetes and Istio. See the following pages for installing KVM-related tools, minikube, kubectl, and istioctl on Ubuntu:
- Installing KVM-related tools on Ubuntu
- Installing
kubectl - Installing
minikube - Installing
istioctl— runningcurl -L https://istio.io/downloadIstio | sh -, as this page instructs, will extract aistio-1.4.5folder to the current working directory.
In addition, execute minikube config set vm-driver kvm2 to ensure the KVM-based hypervisor is used. And check that all tools have been added to your PATH by ensuring you can execute kubectl version, minikube version, and istioctl version.
For clarity and not necessity, the Kubernetes cluster and Istio mesh will be rebuilt several times during this post, such that a clean slate is achieved. The following steps can be performed to create the reference cluster each topic uses, which are based on this walkthrough in Istio’s documentation. The walkthrough guides operators through setting up automatic mutual TLS, and enforcing various policies over mixed workloads. It will also be noted inline when a new reference cluster should be created for an example:
Create a new Kubernetes cluster:
minikube start --memory=16384 --cpus=4 --kubernetes-version=v1.14.2Install Istio via its Operator:
kubectl apply -f https://istio.io/operator.yamlApply
IstioControlPlaneobject:
kubectl apply -f - <Wait 120 seconds for Istio components to be created.
Apply the Istio demo profile, and enable automatic mutual TLS
istioctl manifest apply --set profile=demo
--set values.global.mtls.auto=true
--set values.global.mtls.enabled=falseCreate the “full” namespace, which will house Pods that have Istio sidecars and TLS client certificates:
kubectl create ns fullCreate two Pods in the “full” namespace, and wait for them to be created. Sample Pods from Istio are used.
kubectl apply -f <(istioctl kube-inject -f istio-1.4.5/samples/httpbin/httpbin.yaml) -n full
kubectl apply -f <(istioctl kube-inject -f istio-1.4.5/samples/sleep/sleep.yaml) -n full- Exec into the “sleep” Pod within the “full” namespace
kubectl get pods -n full
kubectl exec -it SLEEP_POD_NAME /bin/sh -n full -c sleepcurlthe “httpbin” Pod within the “full” namespace from the “sleep” Pod in the same namespace, and note theX-Forwarded-Client-Certresponse header, populated with the “sleep” Pod’s client certificate metadata (i.e. auto mTLS is working).
/ # curl httpbin.full:8000/headers
{
"headers": {
"Accept": "*/*",
"Content-Length": "0",
"Host": "httpbin.full:8000",
"User-Agent": "curl/7.64.0",
"X-B3-Parentspanid": "1fc3b2728d362128",
"X-B3-Sampled": "1",
"X-B3-Spanid": "a535e44fdde2ffa5",
"X-B3-Traceid": "27388be1c233991e1fc3b2728d362128",
"X-Forwarded-Client-Cert": "By=spiffe://cluster.local/ns/full/sa/httpbin;Hash=c4b21a3e248da71ce5053cb225132758b6276eb63a272955c81384908d076be5;Subject="";URI=spiffe://cluster.local/ns/full/sa/sleep"
}
}Create the “legacy” namespace, which will house Pods that do not have Istio sidecars or mutual TLS ceritificates:
kubectl create ns legacyCreate two Pods in the “legacy” namespace
kubectl apply -f istio-1.4.5/samples/httpbin/httpbin.yaml -n legacy
kubectl apply -f istio-1.4.5/samples/sleep/sleep.yaml -n legacy- Within the “sleep” Pod in the “legacy” namespace,
curlthe “httpbin” service in the “full” namespace, and note the lack of aX-Forwared-Client-Certresponse header, indicating that the “sleep” Pod within the “legacy” namespace does not have a client certificate.
kubectl get pods -n legacy
kubectl exec -it -n legacy SLEEP_POD_NAME /bin/sh/ # curl httpbin.full:8000/headers
{
"headers": {
"Accept": "*/*",
"Content-Length": "0",
"Host": "httpbin.full:8000",
"User-Agent": "curl/7.64.0",
"X-B3-Sampled": "1",
"X-B3-Spanid": "22684ed7b0cce0da",
"X-B3-Traceid": "0d58bf15f67e67d422684ed7b0cce0da"
}
}Security Analysis
The following subsections have security analysis of the following Istio features:
- IPv6
- Mutual TLS
- Egress restrictions on Pods
The overall perspective is geared towards a security concious operator who is interested in Istio’s security-related features for limiting their workloads’ network interactions. This post attempts to highlight features’ limits, issues that may be encountered in practice, and mitigation steps.
IPv6 Inbound Packet Processing Issue
IPv6 support in Istio is considered “experimental”, and appears to lack tests.
In at least one case, istio-proxy‘s treament of IPv6 traffic is different than that of IPv4 traffic in a security-critical way. If a wildcard is specified for a Pod’s ports to-be-redirected to Istio, which is the default set during Istio installation, the IPv4 iptables logic for incoming packets will:
Jump packets from the
PREROUTINGchain (i.e. packets have just been received) to an an intermediate table,ISTIO_INBOUND.Apply rules for hardcoded (i.e. SSH) and user-specified exclusions that jump those packets to
RETURN(i.e. stop Istio-related packet processing).Apply a catch-all rule that redirects all remaining inbound traffic to
istio-proxy, by jumping to theISTIO_IN_REDIRECTtable, which has rules to redirect traffic to the proxy’s port.
The IPv6 logic takes those first two steps, but the IPv6 logic does not redirect all remaining traffic to Istio; in this case, the rules within the intermediate ISTIO_INBOUND table are exhausted, and the packet will continue through and beyond the PREROUTING chain (i.e. it is not processed further by Istio).
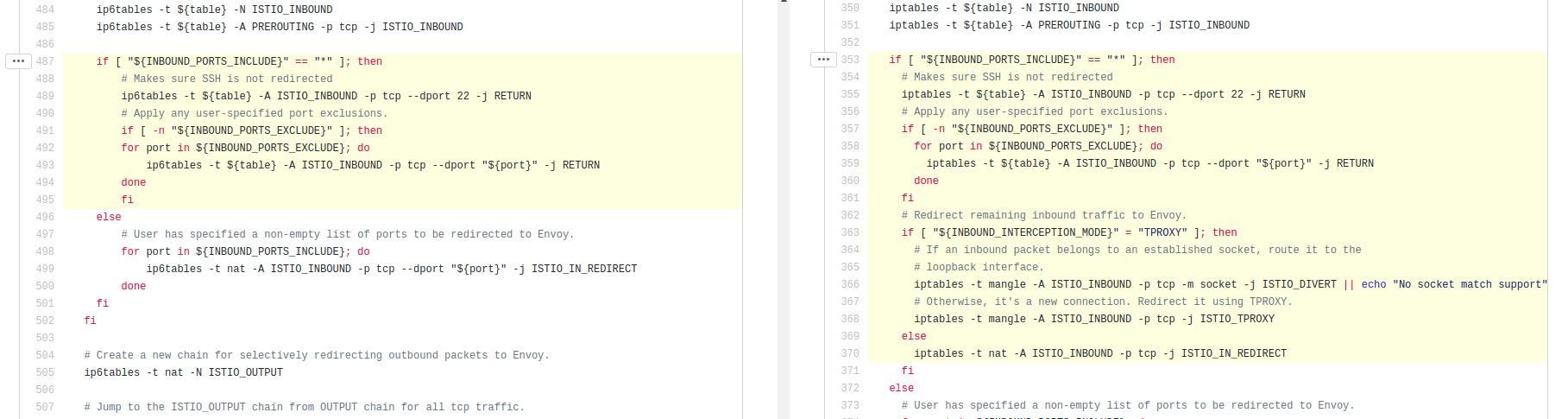
The figure above shows the source code from Istio’s Bash-based iptables setup script, which takes the steps described above. On the left is the IPv6 inbound packet logic, and on the right is the IPv4 logic. As shown and described, if a wildcard is specified for ports to-be-redirected to istio-proxy, the IPv6 code on the left applies the hardcoded SSH and user-supplied port exceptions, and then moves on to installing rules related to outbound packets. In the same branch, IPv4 code on the right applies the hardcoded SSH and user-supplied port exceptions, but then installs a catch-all rule that redirects all remaining traffic to istio-proxy.
Thus, users may expect all inbound IPv6:TCP traffic to be handed to istio-proxy, but the default value of a wildcard for INBOUND_PORTS_INCLUDE does not have this effect for IPv6:TCP traffic. Do note that if users specify a list of ports to be intercepted (not the default), these rules are properly installed by the IPv6 logic; this is the non-default else branch here, as the default is the if branch because a wildcard for INBOUND_PORTS_INCLUDE is the default.
Mutual TLS
One popular aspect of Istio is its ability to automatically provision TLS certificates and allow operators to enforce the use of TLS mutual authentication between services. See the “High-level architecture”, “Istio identity”, and “PKI” sections at https://istio.io/docs/concepts/security/#authentication-architecture for a primer on the components Istio uses during certificate issuance and use.
For this section, we will deploy two simple services into two different Kubernetes namespaces: full, which will host two Pods joined to the Istio mesh and with TLS client certificates; and legacy, which will host two Pods not joined to the Istio mesh (i.e. lack an istio-proxy sidecar) and without TLS client certificates. See the reference cluster section for setup instructions. These examples mirror the following page in Istio’s documentation: https://istio.io/docs/tasks/security/authentication/mtls-migration/.
We will then walk through four ways in which we can unexpectedly reach services inside the full namespace from the legacy namespace (i.e. lacking a TLS client certificate), despite various, associated mutual TLS-based restrictions on such interactions. And we will describe one way in which we can unexpectedly reach Istio’s control plane services from the legacy namespace, despite enabling mutual TLS for control plane services.
AuthenticationPolicy Pitfall
As discussed in the Istio documentation page we have been following (to create the reference cluster), an operator may, after some testing, desire to enforce mutual TLS. That is, Pods in the “full” namespace should only receive mutual TLS connections.
To do so, the documentation page we have been following says: “Run the following command to enforce all Envoy sidecars to only receive mutual TLS traffic”:
kubectl apply -f - <Further, this command is described elsewhere in Istio’s documentation:
This policy specifies that all workloads in the mesh will only accept encrypted requests using TLS. As you can see, this authentication policy has the kind: MeshPolicy. The name of the policy must be default, and it contains no targets specification (as it is intended to apply to all services in the mesh).
After running this kubectl command, we can return to the “sleep” Pod in the “legacy” namespace and observe it can no longer access the “httpbin” Pod in the “full” namespace.
curl httpbin.full:8000/headers
curl: (56) Recv failure: Connection reset by peer
/ # Operators may call it a day here, so it is worth noting that this does not prevent access to TCP ports that are not specified in “httpbin”‘s associated API objects (i.e. what we added to the mesh with kubectl apply -f <(istioctl kube-inject -f istio-1.4.5/samples/httpbin/httpbin.yaml) -n full).
- Exec into the “httpbin” Pod within the “full” namespace
kubectl get pods -n full
kubectl exec -it HTTPBIN_POD_NAME /bin/bash -n full -c httpbin- Inside “httpbin”, start a new copy of its web service on a random TCP port
root@httpbin-76887cf49c-w5xvb:/# ps auxxwww
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 85980 24900 ? Ss 06:58 0:00 /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -k gevent
root 8 0.0 0.2 130360 34716 ? S 06:58 0:00 /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -k gevent
root@httpbin-76887cf49c-w5xvb:/# /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:1337 httpbin:app -k gevent
[1] 20
root@httpbin-76887cf49c-w5xvb:/# [2020-02-20 07:26:55 +0000] [20] [INFO] Starting gunicorn 19.9.0
[2020-02-20 07:26:55 +0000] [20] [INFO] Listening at: http://0.0.0.0:1337 (20)
[2020-02-20 07:26:55 +0000] [20] [INFO] Using worker: gevent
[2020-02-20 07:26:55 +0000] [23] [INFO] Booting worker with pid: 23- Note the “httpbin” Pod’s IP address. Traffic to the “unspecified” port 1337 will not be properly routed if we use the service’s name. It is common for insecure workloads, such as legacy instances in a cloud VPC, to have a direct route to a Pod’s IP.
kubectl get pods -owide -nfull
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
httpbin-76887cf49c-w5xvb 2/2 Running 0 32m 172.17.0.5 minikube
sleep-65b6f697c4-pflm5 2/2 Running 0 32m 172.17.0.7 minikube - Return to a shell in the “sleep” Pod within the “legacy” namespace, and note you can interact with the newly started service in the “full” namespace’s “httpbin” Pod, despite applying an
AuthenticationPolicywhose documentation states that its effect is “all workloads in the mesh will only accept encrypted requests using TLS”.
kubectl exec -it SLEEP_POD_NAME -n legacy /bin/sh
/ # curl 172.17.0.5:1337/headers
{
"headers": {
"Accept": "*/*",
"Host": "172.17.0.5:1337",
"User-Agent": "curl/7.64.0"
}
}
/ # In order to prevent this behavior, an AuthorizationPolicy must be applied to the “httpbin” Pod. If an AuthorizationPolicy is applied to a Pod, traffic is denied by default, so traffic to “unspecified” (i.e. not in the workload’s API objects) is blocked. The following AuthorizationPolicy, noted in Istio’s documentation, will only allow requests from authenticated principals (in our case callers with TLS client certificate):
kubectl apply -f - <Once applying this AuthorizationPolicy, we can see that requests to the the “full” namespace’s “httpbin” Pod’s unspecified TCP port from the “sleep” Pod in the “legacy” namespace fail:
curl 172.17.0.5:1337/headers
curl: (52) Empty reply from server
/ # In this section we saw how following Istio’s prescribed AuthenticationPolicy for enforcing mesh-wide mutual TLS among services fails to protect unspecified TCP ports in an application container (e.g. an application server’s debug interface). To block unauthorized access (i.e. those lacking a TLS client certificate) to such unspecified TCP ports, you must also apply to workloads an AuthorizationPolicy specifying a principals block; a wildcard for principals will allow any caller with a valid TLS client certificate.
AuthorizationPolicy Pitfalls
For the sake of discussion, assume we are now discussing a mesh without any AuthenticationPolicy objects, and in a new reference cluster.
It is worth noting that AuthorizationPolicy objects only have an ALLOW action, and are additive in effect. Concretely, say an operator deploys the following AuthorizationPolicy to ensure that all requests are authenticated with mutual TLS:
kubectl apply -f - <This is mesh-wide in effect, since it specifies Istio’s root namespace in its metadata field. After applying this AuthorizationPolicy, accessing the “httpbin” Pod in the “full” namespace from the “sleep” Pod in the “legacy” namespace fails:
/ # curl httpbin.full:8000/headers
RBAC: access denied/ # However, the following AuthorizationPolicy is subsequently added, which targets the “httpbin” Pod in the “full” namespace, and unintentionally lacks a rule saying the request must be from an authenticated principal:
kubectl -n full apply -f - <The result is that the “sleep” Pod in the “legacy” namespace can now access the “httpbin” Pod in the “full” namespace, because there is a policy that allows the traffic.
curl httpbin.full:8000/headers
{
"headers": {
"Accept": "*/*",
"Content-Length": "0",
"Host": "httpbin.full:8000",
"User-Agent": "curl/7.64.0",
"X-B3-Sampled": "1",
"X-B3-Spanid": "12836faa4a645f69",
"X-B3-Traceid": "7f4e7dcaa944040612836faa4a645f69"
}
}
/ # Technically, in this specific case, the AuthenticationPolicy object listed earlier in AuthenticationPolicy Pitfall would prevent this unintentional exposure because it will be evaluated as well. However, this is not a general mitigation, because AuthorizationPolicy objects are not just used in the context of mutual TLS enforcement (i.e. authentication)—they can be used to express, for example, path- or port-level authorization rules, so the inability to prevent certain namespace or Pod-level exemptions at the mesh-level is something to keep in mind.
As a more holistic fix, the forthcoming Istio 1.5 release will have a DENY action in the AuthorizationPolicy object, which will let operators express DENY rules that will be evaluated before ALLOW rules, and if matched on will cause the traffic to be dropped before any ALLOW rules are evaluated. In this case, an operator can, for example, install DENY action AuthorizationPolicy objects in Istio’s root namespace (defaults to istio-system), and these will not be “overridden” by AuthorizationPolicy objects with ALLOW rules targeting a specific namespace or workload, like we saw above. Operators may wish to use Kubernetes RBAC over Istio’s CRDs to ensure such mesh-level DENY rules cannot be modified by unauthorized users; for example, the Istio root namespace, which defaults to istio-system, is where AuthorizationPolicy objects with mesh-level effects live (they are still a namespace-scoped CRD), and so unauthorized users should not have a RoleBinding to privileges within this namespace. See this post from Istio for more details on the DENY action that will be available in Istio 1.5.
AuthenticationPolicy objects follow this “more specific” precedence, too, so even if there is a MeshPolicy (cluster-scoped CRD) enforcing mutual authentication, it can be overridden at a specific workload (with a namespace-scoped AuthenticationPolicy CRD). This is of interest in multi-tenant scenarios, where a tenant (e.g. business unit A) may have Kubernetes RBAC bindings to modify objects in their Kubernetes namespace (e.g. namespace-scoped AuthenticationPolicy CRDs), but where operators wish to enforce a mesh-wide baseline that cannot be overridden by any tenant.
To see a concrete example of the “more specific” AuthenticationPolicy behvior, in a new reference cluster, apply the following AuthenticationPolicy, which enforces mutual TLS authentication for all workloads in the mesh:
kubectl apply -f - <In the “sleep” Pod within the “legacy” namespace, note you can no longer interact with the “httpbin” Pod in the “full” namespace:
curl httpbin.full:8000/headers
curl: (56) Recv failure: Connection reset by peer
/ # Then, apply the following AuthenticationPolicy, which targets a specifically named workload (“httpbin”) in a specific namespace (“full”), and does not require callers to be authenticated principals:
cat <Now, in the “sleep” Pod within the “legacy” namespace, send a request to the “httpbin” Pod within the “full” namespace, and note this is successful, indicating that the MeshPolicy requiring mutual TLS authentication for all workloads (a cluster-scoped CRD) has been overridden by a more-specific AuthenticationPolicy object (a namespace-scoped CRD):
/ # curl httpbin.full:8000/headers
{
"headers": {
"Accept": "*/*",
"Content-Length": "0",
"Host": "httpbin.full:8000",
"User-Agent": "curl/7.64.0",
"X-B3-Sampled": "1",
"X-B3-Spanid": "94070a3cfead3064",
"X-B3-Traceid": "f200c41073fdc90194070a3cfead3064"
}
}In this section we saw how precedence in evaluation of AuthorizationPolicy and AuthenticationPolicy objects can result in an operator’s intended mesh-wide security baseline being overridden at the namespace or service-level, and the latter requires less broad Kubernetes RBAC permissions.
UDP Pitfall
As we discussed in the beginning of the blog post, Istio only “hooks” TCP traffic, and it does not support UDP traffic, so UDP traffic will be passed to services inside the Pod, unless NetworkPolicy objects are added to drop this traffic. What may not be clear to users is this is the case even if the aforementioned mutual TLS-related AuthorizationPolicy and AuthenticationPolicy objects are defined:
- In a new reference cluster, apply the following:
kubectl apply -f - <kubectl apply -f - <Based on the examples we walked through earlier, this combination of an AuthenticationPolicy and AuthorizationPolicy applied to all workloads in the mesh should be our best bet for ensuring access to any workload requires a valid TLS client certificate.
- Then, inside the “httpbin” Pod within the “full” namespace, install
netcat, start a UDP listener, and keep the terminal window open:
kubectl get pods -n full
kubectl exec -it -n full HTTPBIN_POD_NAME /bin/bash -c httpbin
apt update; apt install -y netcat
nc -luv -p1111- Note the “httpbin” Pod’s IP address:
kubectl get pods -n full -owide
kubectl get pods -n full -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
httpbin-76887cf49c-sh2hz 2/2 Running 0 4m23s 172.17.0.6 minikube
sleep-65b6f697c4-2qwjh 2/2 Running 0 4m18s 172.17.0.7 minikube - Inside the “sleep” Pod within the “legacy” namespace, connect to the “full” namespace’s “httpbin” Pod’s UDP service started in step two:
kubectl get pods -n legacy
kubectl exec -it SLEEP_POD_NAME -n legacy /bin/sh
nc -vu 172.17.0.6 1111- Note that the “httpbin” Pod in the “full” namespaces receives what is typed into the “legacy” namespace’s “sleep” Pod’s
netcat:

controlPlaneSecurityEnabled Bypass
Istio has a configuration directive, controlPlaneSecurityEnabled, which will be enabled by default in the forthcoming Istio 1.5 relase. This enables, but does not enforce, mutual TLS among control plane components (e.g. Pilot, Galley). And in fact, plaintext connections from a Pod lacking an istio-proxy sidecar to control plane components are allowed despite also applying (to e.g. Pilot) an AuthenticationPolicy and MeshPolicy object enforcing the use of mutual TLS (as we walked through earlier for “httpbin”), indicating that AuthorizationPolicy objects have no effect on the control plane components. For example, a Pod without an istio-sidecar proxy or TLS client certificate is still able to interact with Pilot’s debug endpoint, which allows retrieving various information from the cluster, including the Envoy configuration of istio-proxy sidecars in the mesh. See this GitHub issue for more details and reproduction steps.
Egress Restrictions
Another common ask of Isito is how to limit egress traffic. That is, how can I prevent my Pods from sending traffic outside of the mesh (e.g. the Internet)? Istio has several blog posts on this topic.1 2 3 4 They all have some variation of the following language:
A malicious application can bypass the Istio sidecar proxy and access any external service without Istio control. — https://istio.io/docs/tasks/traffic-management/egress/egress-control/#security-note
Istio gives detailed advice for how this can be addressed—namely, Kubernetes NetworkPolicy objects must be used in conjunction with Istio’s own egress restrictions, and Istio’s documentation gives concrete examples of the NetworkPolicy objects to apply.
However, continuing with the theme of this post, the curious reader may be wondering: how difficult is it for a “malicious” application container to bypass the istio-proxy sidecar? Several examples come to mind, and we can illustrate them by creating a new reference cluster and then drawing on examples from this Istio guide; that is, we will enable in-Istio egress restrictions and will not apply NetworkPolicy objects.
Create a test Pod with:
kubectl apply -n default -f <(istioctl kube-inject -f istio-1.4.5/samples/sleep/sleep.yaml)Ensure Istio’s
global.outboundTrafficPolicy.modeis set toALLOW_ANY, which does not enable any restrictions in theistio-proxysidecar around external traffic:
kubectl get configmap istio -n istio-system -o yaml | grep -o "mode: ALLOW_ANY"
mode: ALLOW_ANY
mode: ALLOW_ANY- Send some traffic to the Internet with
curlfrom the “sleep” Pod in the “default” namespace, note that is successful, and also installbind-tools:
kubectl get pods -n default
kubectl exec -n default -it SLEEP_POD_NAME /bin/sh -c sleep
curl -L https://google.com
apk update; apk add bind-tools- Change Istio’s
global.outboundTrafficPolicy.modetoREGISTRY_ONLY, which instructs theistio-proxysidecar to limit traffic to known services (such as this example). It may take about one minute to propagate toistio-proxy.
kubectl get configmap istio -n istio-system -o yaml | sed 's/mode: ALLOW_ANY/mode: REGISTRY_ONLY/g' | kubectl replace -n istio-system -f -- Attempt to send traffic to the Internet from the “sleep” Pod in the “default” namespace again, and note this is blocked:
/ # curl -L https://google.com
curl: (35) OpenSSL SSL_connect: SSL_ERROR_SYSCALL in connection to google.com:443
/ # Next, we will see various way this REGISTRY_ONLY egress restriciton can be bypassed by a “malicious” application container.
UDP-based Bypass
Use dig to perform a DNS query (i.e. UDP traffic) from the “sleep” Pod in the “default” namespace, and note that this traffic successfully reaches the Internet, despite the REGISTRY_ONLY value for global.outboundTrafficPolicy.mode. This is the same istio-proxy sidecar behavior discussed earlier—it will not “hook” UDP traffic, and thus it is not limited by the REGISTRY_ONLY filtering performed by the istio-proxy sidecar because this traffic is not rerouted to the istio-proxy sidecar.
dig @8.8.8.8 www.google.com
...snip...
;; ANSWER SECTION:
www.google.com. 279 IN A 216.58.195.68
;; Query time: 6 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Thu Feb 20 10:19:42 UTC 2020
;; MSG SIZE rcvd: 59ICMP-based Bypass
Use ping to send ICMP traffic from the “sleep” Pod in the “default” namespace, which is not handled and is passed through, just like the UDP example above, bypassing REGISTRY_ONLY.
/ # ping -c1 8.8.8.8
PING 8.8.8.8 (8.8.8.8): 56 data bytes
64 bytes from 8.8.8.8: seq=0 ttl=53 time=7.289 ms
--- 8.8.8.8 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 7.289/7.289/7.289 ms
/ # UID 1337-based Bypass
The istio-proxy sidecar container runs in the Pod under UID 1337, and since it is common for containers to have the CAP_SETUID capability (Docker, Kubernetes’ default container runtime, does not drop it), we can change to UID 1337 from our application container, for which no restrictions are programmed by the proxy:
In the same “sleep” Pod, where a curl from the application container is blocked by REGISTRY_ONLY (see step five here), add a new user whose UID is 1337 (create a bogus password to satisfy adduser):
/ # adduser --uid 1337 envoyuser
Changing password for envoyuser
New password:
Retype password:
passwd: password for envoyuser changed by root
/ # su - envoyuser
sleep-65b6f697c4-hbcch:~$ curl -L https://google.com
Docker does not support ambient capabilities, but running processes in Pods as root is common, and one could argue it is the default, as, unless otherwise specified, Kubernetes will use the container image’s metadata to pick the genesis UID and Docker images default to root.
Besides oft-granted capabilities, a Pod’s spec can specify a UID to run its containers under, and operators can place restrictions around specified UIDs with Pod Security Policies. A common pattern is to use the MustRunAsNonRoot directive, which enforces the use of a non-zero UID. However, with this in place, a user can still specify a UID of 1337 to bypass Istio’s REGISTRY_ONLY egress mode. The behavior is the same as above, but no capability is required, as the user relies on the runtime to run the workload under the 1337 UID that is not beholden to REGISTRY_ONLY egress restrictions.
Namespace and Capability Esoterica
There are a number of ways where Linux capabilities and namespaces accessible to containers in a Pod could allow for a bypass of Istio’s REGISTRY_ONLY egress enforcement.
If an application container has the CAP_NET_ADMIN capability, it can re-program iptables rules in its network namespace, thus bypassing the istio-proxy‘s REGISTRY_ONLY enforcement, because it can reprogram the iptables rules noted earlier in order to have TCP traffic bypass the istio-proxy sidecar proxy (where REGISTRY_ONLY is enforced).
The CAP_NET_ADMIN capability is not granted by Docker or Kubernetes by default, so an operator would have to add this capability to their application container. The CAP_NET_ADMIN capability would not allow a Pod to bypass Kubernetes NetworkPolicy objects, since those reside in the Node’s network namespace, which cannot be accessed unless a Pod has enough privileges to break out entirely (e.g. CAP_SYS_ADMIN is required to issue setns(2)).
The directive shareProcessNamespace, whose Kubernetes API server support is enabled by default, can be specified in a Pod spec (it is not used by default), which puts all containers in a Pod into the same PID namespace. Usage of this directive cannot be restricted with Pod Security Policies, and, if specified in a Pod’s spec, can allow containers to read each others’ filesystem objects and environment variables. Kubernetes’ documentation points out a specific case relating to the /proc/$pid/root link, which “means that filesystem secrets are protected only by filesystem permissions.” More concretely, processes that share a PID namespace can reference (but not necessarly access) each others’ entries in procfs. However, procfs has varying permissions checks on its entries. For example, the /proc/pid/root entry is a symbolic link to a given process’s root file system, which can be used to access files whose permissions are broad (i.e. a reference to another container’s filesystem is achived). However, the /proc/pid/root entry itself has more strict permissions requirements, which are detailed in the proc(5) man page: access to the /proc/pid/root link requires PTRACE_MODE_READ_FSCREDS, whose requirements are detailed in the ptrace(2) man page:

A general Kubernetes container will not have the CAP_SYS_PTRACE capability with respect to step three in the figure above (it is not granted by default), so in order to access a sidecar’s filesystem through the /proc/pid/root link, it must run under the same UID as the sidecar’s processes, by specifying it in a Pod’s spec as described earlier, or by changing to the sidecar’s UID with CAP_SETUID (granted by default in Docker and Kubernetes). A container lacking CAP_SETUID (through set evaluation or no_new_privs) and running as a different UID than its sidecar (even UID 0) generally cannot access said sensitive entries (e.g., /proc/pid/root, /proc/pid/environ) in procfs. So shareProcessNamespace is not an interesting way to bypass the istio-proxy sidecar’s egress restrictions, because in order to explore the sidecar’s filesystem, for example, we already need to exist under its UID 1337 through CAP_SETUID or through the RunAsUser Pod spec directive, and if this is the case, no egress rules are applied anyway, as we saw earlier when we switched to UID 1337. Do note that /proc/pid/cmdline does not require such ptrace(2)-related access checks, and can be read by any other process in the PID namespace. This is useful to keep in mind, as tokens and passwords are often passed as flags at a program’s invocation, so they will show up in /proc/pid/cmdline.
Conclusion
In this blog post we used lab-based examples to illustrate common misconceptions and pitfalls encountered when using Istio to limit workloads’ network traffic:
“unsupported” traffic, such as UDP and ICMP, makes it through to workloads ostensibly protected by Istio’s most strict mutual TLS configuration, and operators have no indication this is occuring (e.g. an Istio log message on inbound UDP packets when mutual TLS is enforced); Kubernetes NetworkPolicy objects must be used to drop such traffic.
IPv6 is not well-supported in Istio, and appears to have security-relevant issues; for the time being it should be classified as “unsupported” traffic.
Setting just the prescribed mesh-wide AuthenticationPolicy for mutual TLS leaves TCP ports not specified in a workload’s API objects accessible; you need an AuthorizationPolicy to touch the workload for these “unspecified” ports to be blocked.
Operators cannot express mesh-wide AuthorizationPolicy rules that cannot be superseded by namespace or Pod-specific exemptions, but support for this case with the DENY action is coming in Istio 1.5.
AuthenticationPolicy objects also have a precedence in their order of operations, and namespace or workload-scoped policy is always able to override cluster-scoped policy; if an operator wishes to prevent such overriding exemptions, prevent access to AuthenticationPolicy CRDs altogether with Kubernetes RBAC.
To robustly enforce external egress controls, Kubernetes NetworkPolicy objects must be used, since they will handle all types of traffic, and cannot be bypassed by a misbehaving Pod, as they exist in the Node’s network namespace, which cannot be accessed through privileges commonly granted to Pods
The shareProcessNamespace Pod spec directive can have unintended effects if security is enforced in a sidecar container, and especially when care is not taken to restrict usage of capabilities (e.g. CAP_SETUID, SYS_PTRACE), which can allow dangerous interactions with the sidecar container’s procfs entries visible to the application container due to the shared PID namespace; usage of the shareProcessNamespace directive cannot be restricted by a Pod Security Policy, but it can be with an Admission-related tool, such as k-rail, though in general the security boundary between containers in a Pod is weak, since various Linux namespaces are shared by design.
Istio’s controlPlaneSecurityEnabled directive does not behave as most users would expect, and, when enabled, still allows plaintext, non-authenticated traffic to various control plane endpoints; operators can mitigate this by using NetworkPolicy objects to limit connections from untrusted workloads into the Istio control plane, but note that ports in-use by Istio’s control plane are not always fully documented (e.g. Pilot will use port 15012 in Istio 1.5, but this is not documented).
An overall point to recognize is Istio, generally, must be paired with Kubernetes NetworkPolicy objects in order to achieve a secure result.
Like many tools with a large set of flexible features, Istio receives security review and support, but its features’ behaviors may not be intuitive, or behave as one would expect. As a general point, it is always good to evaluate new infrastructure features (and especially security-related ones) with a critical eye, and to understand the internals of such features’ implementations, such that their limits and potential applications can be correctly understood.
